- Products

- Developers
- User stories
- Blog
- Pricing

Build a web scraper with Node
Introduction
Web scraping refers to the process of gathering information from a website through automated scripts. This eases the process of gathering large amounts of data from websites where no official API has been defined.
The process of web scraping can be broken down into two main steps:
- Fetching the HTML source code of the website through an HTTP request or by using a headless browser.
- Parsing the raw data to extract just the information you're interested in.
We'll examine both steps during the course of this tutorial. At the end of it all, you should be able to build a web scraper for any website with ease.
Prerequisites
To complete this tutorial, you need to have Node.js (version 8.x or later) and npm installed on your computer. This page contains instructions on how on how to install or upgrade your Node installation to the latest version.
Getting started
Create a new scraper directory for this tutorial and initialize it with a package.json file by running npm init -y from the project root.
Next, install the dependencies that we'll be needing too build up the web scraper:
npm install axios cheerio puppeteer --save
Here's what each one does:
- Axios: Promise-based HTTP client for Node.js and the browser
- Cheerio: jQuery implementation for Node.js. Cheerio makes it easy to select, edit, and view DOM elements.
- Puppeteer: A Node.js library for controlling Google Chrome or Chromium.
You may need to wait a bit for the installation to complete as the puppeteer package needs to download Chromium as well.
Scrap a static website with Axios and Cheerio
To demonstrate how you can scrape a website using Node.js, we're going to set up a script to scrape the Premier League website for some player stats. Specifically, we'll scrape the website for the top 20 goalscorers in Premier League history and organize the data as JSON.
Create a new pl-scraper.js file in the root of your project directory and populate it with the following code:
1// pl-scraper.js 2 3 const axios = require('axios'); 4 5 const url = 'https://www.premierleague.com/stats/top/players/goals?se=-1&cl=-1&iso=-1&po=-1?se=-1'; 6 7 axios(url) 8 .then(response => { 9 const html = response.data; 10 console.log(html); 11 }) 12 .catch(console.error);
If you run the code with node pl-scraper.js, a long string of HTML will be printed to the console. But how can you parse the HTML for the exact data you need? That's where Cheerio comes in.
Cheerio allows us to use jQuery methods to parse an HTML string and extract whatever information we want from it. But before you write any code, let’s examine the exact data that we need through the browser dev tools.
Open this link in your browser, and open the dev tools on that page. Use the inspector tool to highlight the body of the table listing the top goalscorers in Premier League history.
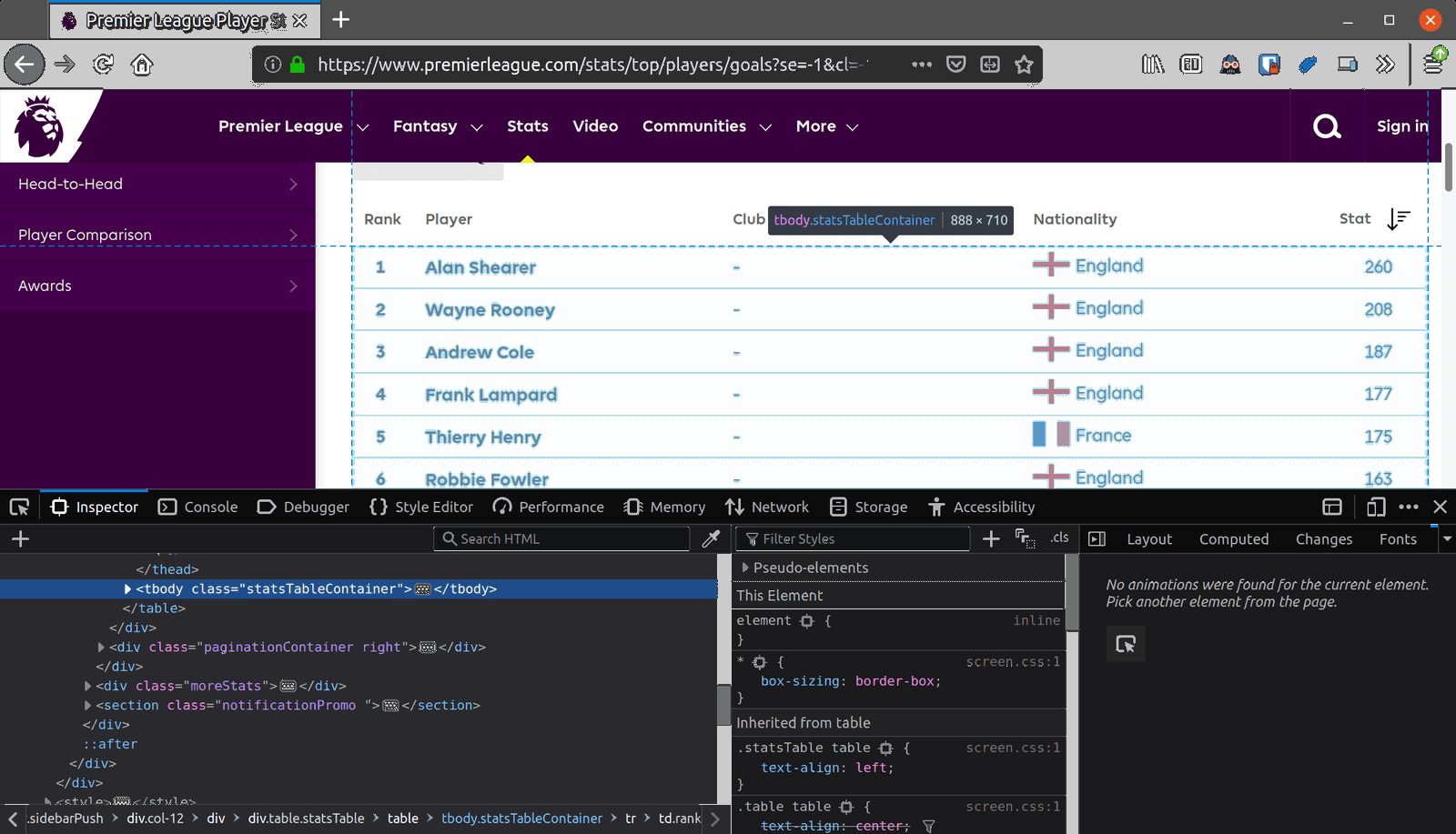
As you can see the table body has a class of .statsTableContainer. We can select all the rows using cheerio like this: $('.statsTableContainer > tr'). Go ahead and update the pl-scraper.js file to look like this:
1// pl-scraper.js 2 3 const axios = require('axios'); 4 const cheerio = require('cheerio'); 5 6 const url = 'https://www.premierleague.com/stats/top/players/goals?se=-1&cl=-1&iso=-1&po=-1?se=-1'; 7 8 axios(url) 9 .then(response => { 10 const html = response.data; 11 const $ = cheerio.load(html); 12 const statsTable = $('.statsTableContainer > tr'); 13 console.log(statsTable.length); 14 }) 15 .catch(console.error);
Unlike jQuery which operates on the browser DOM, you need to pass in the HTML document into Cheerio before we can use it to parse the document with it. After loading the HTML, we select all 20 rows in .statsTableContainer and store a reference to the selection in statsTable. You can run the code with node pl-scraper.js and confirm that the length of statsTable is exactly 20.
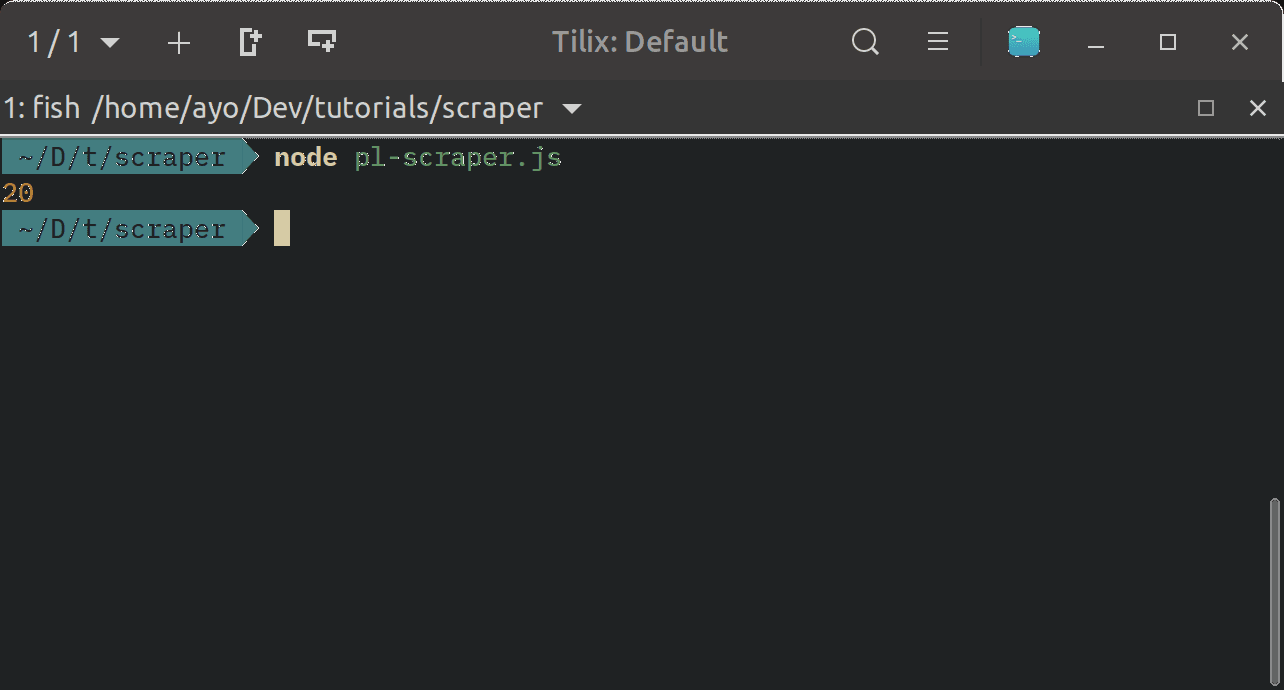
The next step is to extract the rank, player name, nationality and number of goals from each row. We can achieve that using the following script:
1// pl-scraper.js 2 3 const axios = require('axios'); 4 const cheerio = require('cheerio'); 5 6 const url = 'https://www.premierleague.com/stats/top/players/goals?se=-1&cl=-1&iso=-1&po=-1?se=-1'; 7 8 axios(url) 9 .then(response => { 10 const html = response.data; 11 const $ = cheerio.load(html) 12 const statsTable = $('.statsTableContainer > tr'); 13 const topPremierLeagueScorers = []; 14 15 statsTable.each(function () { 16 const rank = $(this).find('.rank > strong').text(); 17 const playerName = $(this).find('.playerName > strong').text(); 18 const nationality = $(this).find('.playerCountry').text(); 19 const goals = $(this).find('.mainStat').text(); 20 21 topPremierLeagueScorers.push({ 22 rank, 23 name: playerName, 24 nationality, 25 goals, 26 }); 27 }); 28 29 console.log(topPremierLeagueScorers); 30 }) 31 .catch(console.error);
Here, we are looping over the selection of rows and using the find() method to extract the data that we need, organize it and store it in an array. Now, we have an array of JavaScript objects that can be consumed anywhere else.
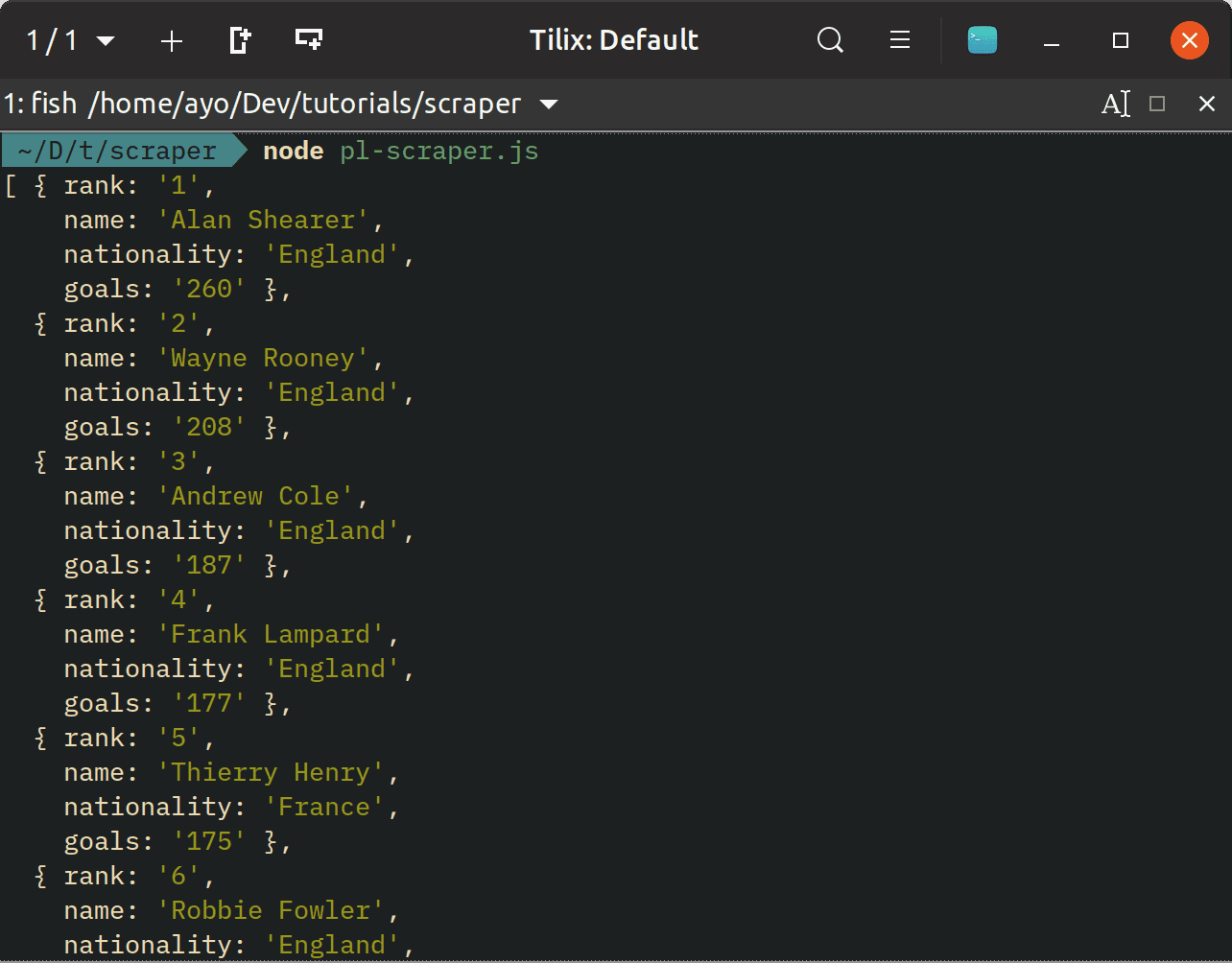
Scrape a dynamic website using Puppeteer
Some websites rely exclusively on JavaScript to load their content, so using an HTTP request library like axios to request the HTML will not work because it will not wait for any JavaScript to execute like a browser would before returning a response.
This is where Puppeteer comes in. It is a library that allows you to control a headless browser from a Node.js script. A perfect use case for this library is scraping pages that require JavaScript execution.
Let’s examine how Puppeteer can help us scrape news headlines from r/news since the newer version of Reddit requires JavaScript to render content on the page.
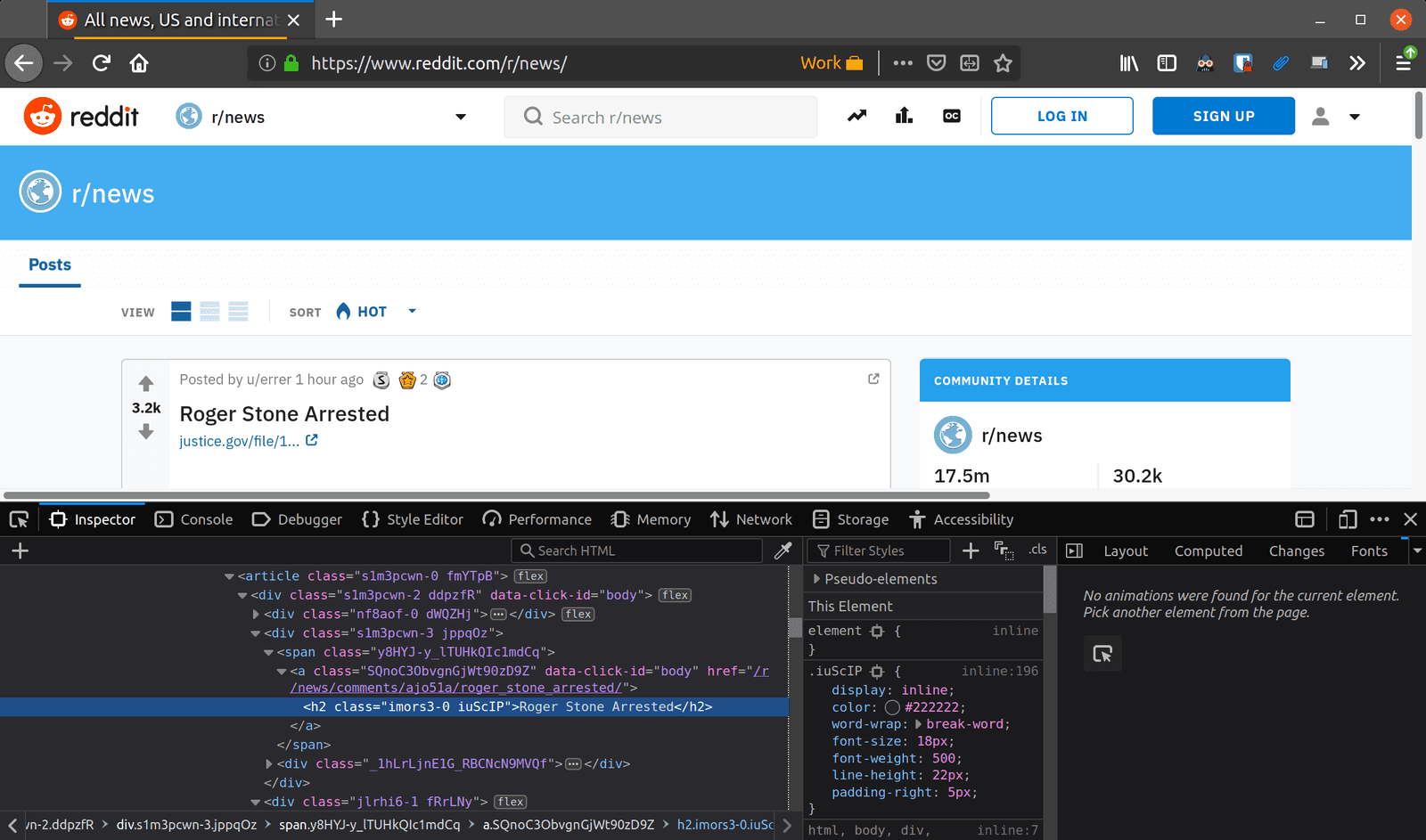
It appears, the headlines are wrapped in an anchor tag that links to the discussion on that headline. Although the class names have been obfuscated, we can select each headline by targeting each h2 inside any anchor tag that links to the discussion page.
Create a new reddit-scraper.js file and add the following code into it:
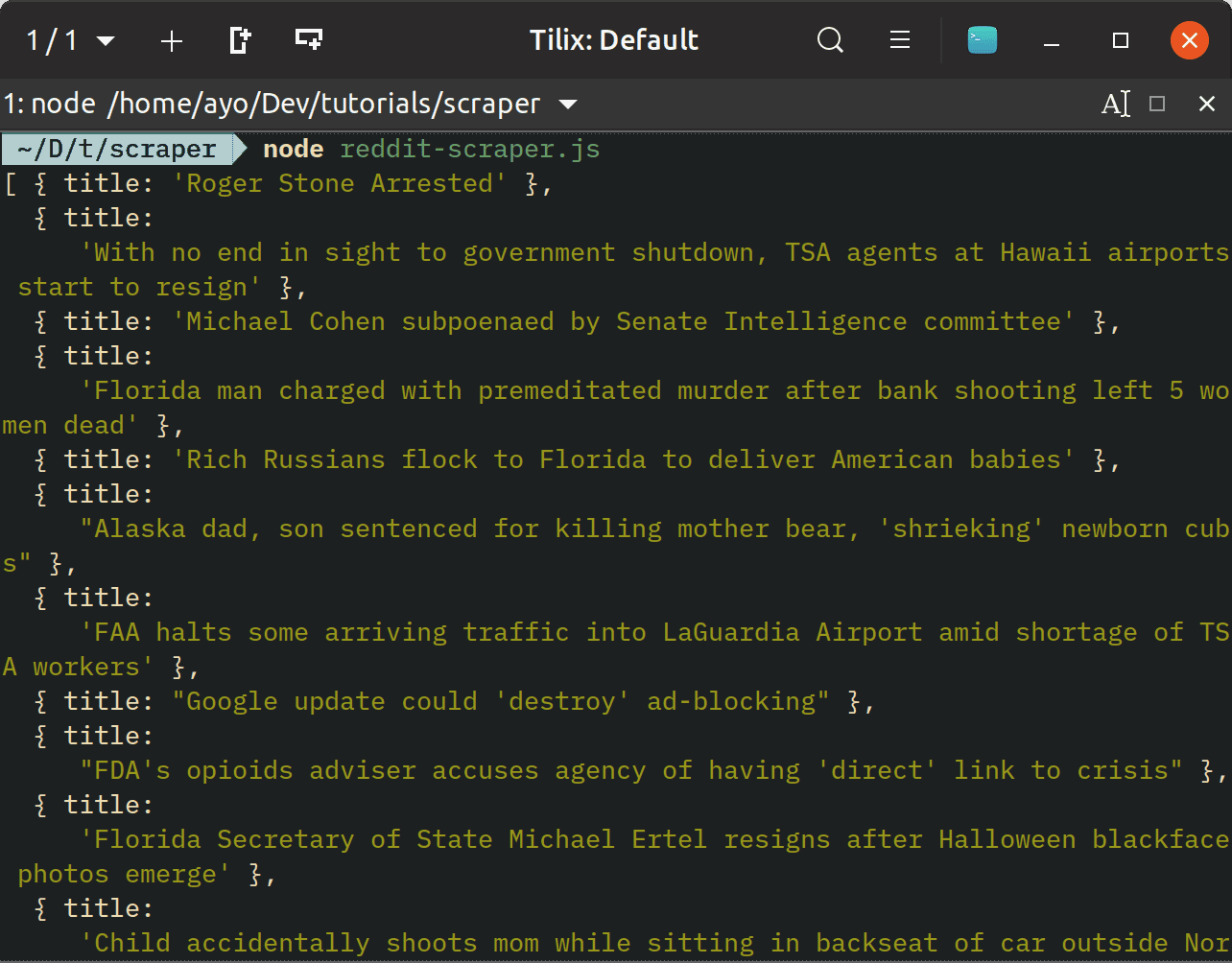
1// reddit-scraper.js 2 3 const cheerio = require('cheerio'); 4 const puppeteer = require('puppeteer'); 5 6 const url = 'https://www.reddit.com/r/news/'; 7 8 puppeteer 9 .launch() 10 .then(browser => browser.newPage()) 11 .then(page => { 12 return page.goto(url).then(function() { 13 return page.content(); 14 }); 15 }) 16 .then(html => { 17 const $ = cheerio.load(html); 18 const newsHeadlines = []; 19 $('a[href*="/r/news/comments"] > h2').each(function() { 20 newsHeadlines.push({ 21 title: $(this).text(), 22 }); 23 }); 24 25 console.log(newsHeadlines); 26 }) 27 .catch(console.error);
This code launches a puppeteer instance, navigates to the provided URL, and returns the HTML content after all the JavaScript on the page has bee executed. We then use Cheerio as before to parse and extract the desired data from the HTML string.
Wrap up
In this tutorial, we learned how to set up web scraping in Node.js. We looked at scraping methods for both static and dynamic websites, so you should have no issues scraping data off of any website you desire.
You can find the complete source code used for this tutorial in this GitHub repository.






© 2026 Pusher Ltd. All rights reserved.
Pusher Limited is a company registered in England and Wales (No. 07489873) whose registered office is at MessageBird UK Limited, 3 More London Riverside, 4th Floor, London, United Kingdom, SE1 2AQ.