- Products

- Developers
- User stories
- Blog
- Pricing

Clean architecture for the rest of us
- Introduction
- Preface
- What is clean architecture?
- Characteristics of a clean architecture
- Defining terms
- Entities
- Use cases
- Adapters
- Infrastructure
- Principles for implementing clean architecture
- Single Responsibility Principle (SRP)
- Open Closed Principle (OCP)
- Liskov Substitution Principle (LSP)
- Interface Segregation Principle (ISP)
- Dependency Inversion Principle (DIP)
- Reuse/Release Equivalence Principle (REP)
- Common Closure Principle (CCP)
- Common Reuse Principle (CRP)
- Acyclic Dependency Principle (ADP)
- Stable Dependency Principle (SDP)
- Stable Abstraction Principle (SAP)
- Final notes
- Testing
- Dividing components by use cases
- Enforcing a division of layers
- Only add complexity as you need it
- Details
- Last bits of advice
- Exercise: Make a dependency graph
- Conclusion
- Further study
Introduction
If you are a master software engineer, you can stop reading. This post isn't for you. This post is for people who are like me, mediocre programmers who write messy code and create spaghetti architecture but are fascinated with the idea of building something clean, maintainable, and adaptable.
Preface
I don't usually buy computer books because they get outdated so quickly. Besides, I can find all the information online anyway. A year ago, though, I started reading Clean Code by Robert Martin. It really improved how I developed software, so when I saw that another book by the same author had come out, one called Clean Architecture, I was quick to pick it up.
Like Clean Code, Clean Architecture is filled with timeless principles that can be applied no matter what language someone is coding in. If you do a search online for the title of the book, you will find people who disagree with the author. Critiquing his views is not what I will be doing here, though. I only know that Robert Martin (aka Uncle Bob) has been programming for 50 years and I haven't.
The book was a bit difficult to understand, though, so I will do my best to summarize and explain the important concepts at a level that normal people can understand. I am still growing as a software architect, so read everything I write with a critical eye.
What is clean architecture?
Architecture means the overall design of the project. It's the organization of the code into classes or files or components or modules. And it's how all these groups of code relate to each other. The architecture defines where the application performs its core functionality and how that functionality interacts with things like the database and the user interface.
Clean architecture refers to organizing the project so that it's easy to understand and easy to change as the project grows. This doesn't happen by chance. It takes intentional planning.
Characteristics of a clean architecture
The secret to building a large project that is easy to maintain is this: separating the files or classes into components that can change independently of other components. Let's illustrate that with a couple of images.

In the image above, if you want to replace the scissors with a knife, what do you have to do? You have to untie the strings that go to the pen, the ink bottle, the tape and the compass. Then you have to retie those items to a knife. Maybe that works for the knife, but what if the pen and the tape say, "Wait, we needed scissors." So now the pen and the tape don't work and have to be changed, which in turn affects the objects tied to them. It's a mess.
Compare that to this:

Now how do we replace the scissors? We only have to pull the scissors’ string out from under the Post-it notes and add a new string that is tied to a knife. Way easier. The Post-it notes don't care because the string wasn't even tied to it.
The architecture represented by the second image was obviously easier to change. As long as the Post-it notes don't need to be changed often, this system will be very easy to maintain. This same concept is the architecture that will make your software easy to maintain and change.
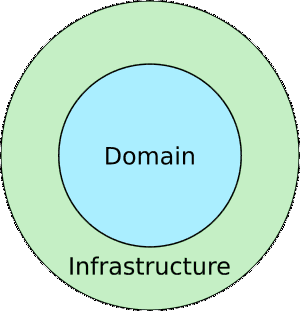
The inner circle is the domain layer of your application. This is where you put the business rules. By "business" we don't necessarily mean a company. It just means the essence of what your application does, the core functionality of the code. A translation app translates. An online store has products to sell. These business rules tend to be fairly stable since you are not likely to change the essence of what your app does very often.
The outer circle is the infrastructure. It includes things like the UI, the database, web APIs, and frameworks. These things are more likely to change than the domain. For example, you are more likely to change how a UI button looks than you are to change how a loan is calculated.
A boundary between the domain and the infrastructure is set up so that the domain doesn't know anything about the infrastructure. That means the UI and the database depend on the business rules, but the business rules don't depend on the UI or database. This makes it a plugin architecture. It doesn't matter if the UI is a web interface, a desktop app, or a mobile app. It doesn't matter if the data is stored using SQL or NoSQL or in the cloud. The domain doesn't care. This makes it easy to change the infrastructure.
Defining terms
The two circles in the image above can be further refined.
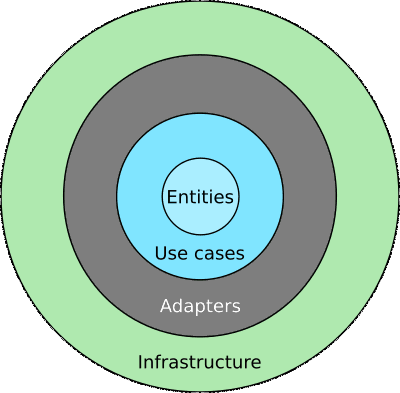
Here the domain layer is subdivided into entities and use cases, and an adapter layer forms the border between the domain and the infrastructure layer. These terms can be a little confusing. Let's look at them individually.
Entities
An entity is a set of related business rules that are critical to the function of the application. In an object oriented programming language the rules for an entity would be grouped together as methods in a class. Even if there were no application, these rules would still exist. For example, charging 10% interest on a loan is a rule that a bank might have. This would be true whether the interest was calculated on paper or using a computer. Here is an example from the book of what an entity class might look like (p. 191):

The entities know nothing of the other layers. They don't depend on anything. That is, they don't use the names of any other classes or components that are in the outer layers.
Use cases
The use cases are the business rules for a specific application. They tell how to automate the system. This determines the behavior of the app. Here is an example from the book of the business rules for a use case (p. 192, somewhat modified):
1Gather Info for New Loan 2 3 Input: Name, Address, Birthdate, etc. 4 Output: Same info + credit score 5 6 Rules: 7 1. Validate name 8 2. Validate address, etc. 9 3. Get credit score 10 4. If credit score < 500 activate Denial 11 5. Else create Customer (entity) and activate Loan Estimation
The use cases interact with and depend on the entities, but they know nothing about the layers further out. They don't care if it's a web page or an iPhone app. They don't care if the data is stored in the cloud or in a local SQLite database.
This layer defines interfaces or has abstract classes that outer layers can use.
Adapters
The adapters, also called interface adapters, are the translators between the domain and the infrastructure. For example, they take input data from the GUI and repackage it in a form that is convenient for the use cases and entities. Then they take the output from the use cases and entities and repackage it in a form that is convenient for displaying in the GUI or saving in a database.
Infrastructure
This layer is where all the I/O components go: the UI, database, frameworks, devices, etc. It's the most volatile layer. Since the things in this layer are so likely to change, they are kept as far away as possible from the more stable domain layers. Because they are kept separate, it's relatively easy make changes or swap one component for another.
Principles for implementing clean architecture
Because some of the following principles have confusing names, I purposefully didn't use them in my explanation above. However, following these principles is how you achieve the architectural design that I described. If this section makes your head spin, you can skip down to the final notes section.
The first five principles below are often abbreviated as SOLID to help you remember them. They are class level principles but have similar counterparts that apply to components (groups of related classes). The component level principles follow the SOLID principles.
Single Responsibility Principle (SRP)
This is the S of SOLID. SRP says that a class should only have one job. It may have multiple methods, but these methods all work together to do one main thing. The class should only have one reason to change. For example, if the finance office has one requirement that will change the class and the human resources department has a another requirement that will change the class in a different way, then there are two reasons to change. The class should be divided into two separate classes, each with only one reason to change.
Open Closed Principle (OCP)
This is the O of SOLID. Open means open for extension. Closed means closed for modification. So you should be able to add functionality to a class or component, but you shouldn't need to modify existing functionality. How do you do that? You make sure that every class or component has just one responsibility and then you hide the more stable classes behind interfaces so that they won't be affected when less stable classes have to change.
Liskov Substitution Principle (LSP)
This is the L of SOLID. I guess they needed the L to spell SOLID, but "substitution" is all you need to remember. This principle means that lower level classes or components can be substituted without affecting the behavior of the higher level classes and components. This can be done by implementing abstract classes or interfaces. For example, in Java an ArrayList and a LinkedList both implement the List interface so they can be substituted for each other. If this principle were applied on the architectural level, MySQL could be substituted with MongoDB without affecting the domain logic.
Interface Segregation Principle (ISP)
This is the I of SOLID. ISP refers to using an interface to separate a class from the other classes that use it. The interface only exposes the subset of methods that a dependent class needs. That way when there are changes to other methods, they don't affect the dependent class.
Dependency Inversion Principle (DIP)
This is the D of SOLID. This means that less stable classes and components should depend on more stable ones, and not the other way around. If a stable class depends on an unstable class, then every time the unstable class changes, it will also affect the stable class. So the direction of dependency needs to be inverted. How is this done? By using an abstract class or hiding the stable class behind an interface.
So instead of having a stable class use the name of a volatile class like this:
1class StableClass { 2 void myMethod(VolatileClass param) { 3 param.doSomething(); 4 } 5 }
You could make an interface that the volatile class implements:
1class StableClass { 2 interface StableClassInterface { 3 void doSomething(); 4 } 5 void myMethod(StableClassInterface param) { 6 param.doSomething(); 7 } 8 } 9 10 class VolatileClass implements StableClass.StableClassInterface { 11 @Override 12 public void doSomething() { 13 } 14 }
This inverts the dependency direction. The volatile class knows the name of the stable class, but the stable class doesn't know anything about the volatile class.
Using the Abstract Factory pattern is another way to achieve this.
Reuse/Release Equivalence Principle (REP)
REP is a component level principle. Reuse refers to a group of reusable classes or modules. Release refers to publishing it with a version number. This principle says that whatever you release should be reusable as a cohesive unit. It shouldn't be a random collection of unrelated classes.
Common Closure Principle (CCP)
CCP is a component level principle. It says that components should be a collection of classes that change for same reason at the same time. If there are different reasons to change or the classes change at different rates, then the component should be split up. This is basically the same thing as the Single Responsibility Principle above.
Common Reuse Principle (CRP)
CRP is a component level principle. It says that you shouldn't depend on a component that has classes that you don't need. Those components should be split up so that the users don't have to depend on classes that they don't use. This is basically the same thing as Interface Segregation Principle above.
These three principles (REP, CCP, and CRP) are in tension with each other. Too much splitting up or too much grouping can both cause problems. One needs to balance these principles based on the situation.
Acyclic Dependency Principle (ADP)
ADP means that you shouldn't have any dependency cycles in your project. For example, if component A depends on component B, and component B depends on component C, and component C depends on component A, then you have a dependency cycle.
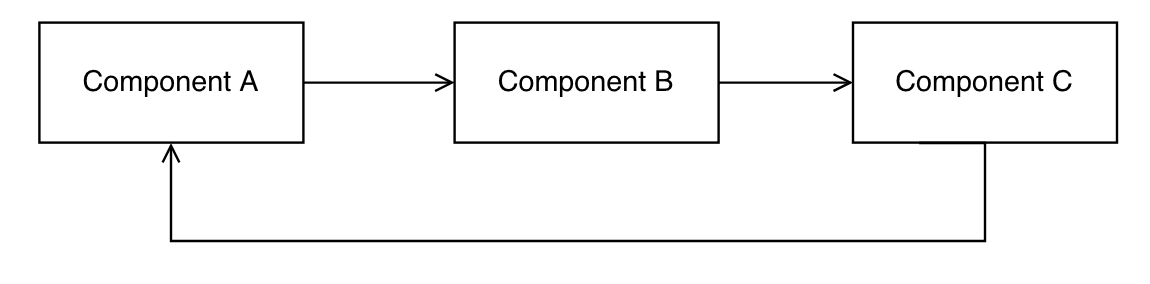
Having such a cycle creates major problems when trying to make changes to the system. One solution to break the cycle is to use the Dependency Inversion Principle and add an interface between components. If different individuals or teams have responsibility for different components, then the components should be individually released with their own versioning numbers. That way changes in one component don't need to immediately affect other teams.
Stable Dependency Principle (SDP)
This principle says that dependencies should be in the direction of stability. That is, less stable components should depend on more stable components. This minimizes the effect of change. Some components are intended to be volatile. That's OK, but you shouldn't make stable components depend on them.
Stable Abstraction Principle (SAP)
SAP says that the more stable a component is, the more abstract it should be, that is, the more abstract classes it should contain. Abstract classes are easier to extend so this keeps stable components from becoming too rigid.
Final notes
The content above summarized the main principles of the Clean Architecture book, but there are a few other important points that I would like to add.
Testing
Creating a plugin architecture has the benefit of making your code much more testable. It's really hard to test your code when there are lots of dependencies. But when you have a plugin architecture, it’s easy to just replace a database dependency (or whatever component) with a mock object.
I've always had a terrible time testing the UI. I make a test that walks through the GUI but as soon as I make a change to the UI the test breaks. So I end up just deleting the test. I learned, though, that I should create a Presenter object in the adapter layer. The Presenter will take the output of the business rules and format everything as the UI view needs it. Then the UI view object does nothing except display the preformatted data that the Presenter provides. With this setup you can test the Presenter code independently of the UI.
Create a special testing API to test the business rules. It should be separate from the interface adapters so that the tests don't break whenever the structure of the application changes.
Dividing components by use cases
I talked about the domain and infrastructure layers above. If you think of these as horizontal layers, they can be vertically sliced into groups of components according to the different use cases that an app might have. It's like a layered cake where each slice is a use case and each layer in the slice makes a component.

For example, on a video site, one use case is the viewer watching the videos. So you have a ViewerUseCase component, a ViewerPresenter component, a ViewerView component, and so on. Another use case is for the publisher who uploads videos to the site. For them you would have a PublisherUseCase component, a PublisherPresenter component, a PublisherView component, and so on. An additional use case might be for the site administrator. In this way individual components get created by vertically slicing the horizontal layers.
When the application is deployed, the components can be grouped in whatever way makes the most sense.
Enforcing a division of layers
You might have the best architecture in the world, but if a new developer comes along and adds a dependency that circumvents your boundaries, this completely defeats the purpose. The best way to prevent this is using the compiler to help you guard your architecture. For example, in Java you can make classes package private in order to hide them from modules that shouldn't know about them. Another option is to use a third-party software that will help you to check whether anything is using something that it shouldn't.
Only add complexity as you need it
Don't over-design your system from the beginning. Only use as much architecture as you need at the time. But within your architecture maintain boundaries that make components easier to break out in the future. For example, to start with you might deploy what is outwardly a monolithic application but on the inside the classes maintain proper boundaries. Later you might break these out into separate modules. Still later you may deploy them as services. As long as you maintain the layers and boundaries along the way, you have the freedom to adjust how they are deployed. In this way you aren't creating unneeded complexity which might never be used.
Details
When starting a project you should work on the business rules first. All the other things are details. The database is a detail. The UI is a detail. The OS is a detail. A web API is a detail. A framework is a detail. Leave the decisions about them undecided for as long as possible. That way by the time you need them you will be in a much better position to make a smart choice. It won't matter to your initial development because the domain layers don't know anything about the infrastructure. When you are ready to choose a database, fill in the database adapter code and plug it in. When you are ready for the UI, fill in the UI adapter code, and plug it in.
Last bits of advice
- Don't use your Entity objects as data structures to pass around in the outer layers. Make separate data model objects for that.
- The top level organization of your project should clearly tell people what your project is all about. This is called screaming architecture.
- Get out and start putting these lessons into practice. It's only by using the principles that you will really learn them.
Exercise: Make a dependency graph
Open one of your current projects and make a dependency graph on a piece of paper. Draw a box for every component or class in your project. Then go through each class and see what that class depends on. Any named class is a dependency. Draw an arrow from the box of the class you are checking to the box of the named class or component.
When you are done going through all of the classes, consider the following questions:
- Where are your business rules (entities and use cases)?
- Do your business rules depend on anything else?
- How many classes or components would it affect if you had to use a different database? UI platform? Framework?
- Are there any dependency cycles?
- What refactoring do you need to do in order to create a plugin architecture?
Conclusion
The essence of the Clean Architecture book was that you need to create a plugin architecture. Classes that might change at the same time and for the same reason should be grouped together into components. The business rule components are more stable and should know nothing about the more volatile infrastructure components, which deal with the UI, database, web, frameworks, and other details. The boundary between component layers is maintained by using interface adapters that translate the data between the layers and keep the dependencies pointing in the direction of the more stable inner components.
I've learned a lot. I hope you have, too. If I misrepresented the book on any point, please let me know. You can find my contact information on my GitHub profile.
Further study
I did my best to fully summarize Clean Architecture, but you will find a lot more information in the book itself. It's worth your time to read it. In fact, I recommend all three of the following books by Robert Martin. I'll link to them on Amazon, but you can probably find them cheaper if you buy a used copy. I listed them in the order that I recommend reading them. These are books that aren’t going to get outdated any time soon.






© 2026 Pusher Ltd. All rights reserved.
Pusher Limited is a company registered in England and Wales (No. 07489873) whose registered office is at MessageBird UK Limited, 3 More London Riverside, 4th Floor, London, United Kingdom, SE1 2AQ.