- Products

- Developers
- User stories
- Blog
- Pricing

How to serve initial state by retrieving cached live data from an application
Find our how your application server is now able to retrieve the current cached data and define its time to live (TTL) using our HTTP API through our server SDKs.
Introduction
Cache channels are a newer feature in Pusher Channels that allow your application server to retrieve the last triggered event and serve it to new users. You can read more about how they work in the Cache channel docs.
Cache channels make it easy to implement initial state. Today we’re taking a look at how to use the HTTP API for cache channels to do just that.
Developing your realtime apps with cache channels
Pusher Channels provides a straightforward model for developers to use. The core concepts are users, connections, channels, and events. To learn how we define these Pusher-specific terms, go to Pusher Glossary.
Let’s break it down. When a user opens an application using Pusher Channels, a connection is established. When that connection subscribes to a channel, the connection will receive every event that is published to that channel from that point on. Until it unsubscribes or disconnects.
A Cache channel remembers the last event published to it and immediately sends it to a connection when the connection subscribes to the channel.
With regular channels, a subscriber is notified only when the next event occurs after they’ve subscribed. This means that new subscribers are not informed of any events which happened before they subscribed to a channel.
For example, if you have a chat app, that’s likely what you want. But if you have a stock tracking app, subscribers need to be able to view stock prices as soon as they join. You cannot have new subscribers waiting for a stock price to change to then trigger an event for them to see the new price.
With cache channels, the user immediately sees the current stock price once they subscribe to the channel.
Breaking it down with an example realtime stock app
Let’s say we need some simple realtime data displayed on our web page: the stock price of a single company.
Here’s how it would work on a business web page using Pusher Channels.
To implement this, our application server would do the following:
- Integrate with an external stock price API and get informed of stock price changes
- Trigger an event on the cache channel for a company every time its stock price changes. If the company name was, for example, Big Trade FX, the channel name could be cache-company-big-trade-fx-stock-price. The cache- prefix indicates that this channel is a cache channel.
Meanwhile, when this company page is opened, our application front-end running on the user browser would do the following:
- Establish a connection with Pusher
- Subscribe to the company stock price channel using the same channel naming scheme as our application server
- Handle incoming events about new stock prices by updating the information presented to the user on the web page
Pusher would then bridge the gap between the application server and the front end by broadcasting the events to all active and subscribed users currently viewing the page in real time.
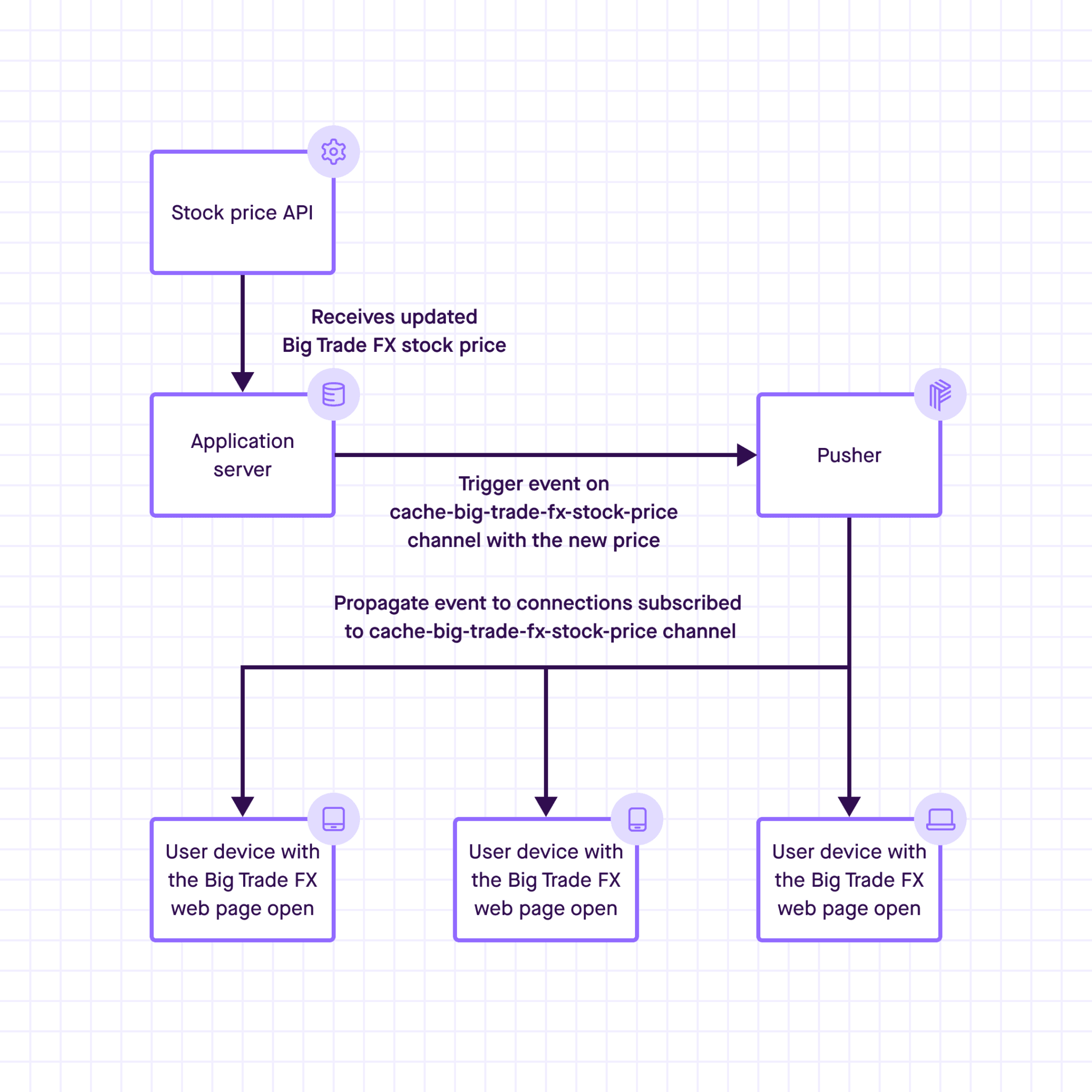
Regular channels and cache channels behave in a similar way with one difference in the moment when a user subscribes to the channel.
The following sequence diagram shows what the cache channel is bringing to the table. The right side of the diagram under cache, indicates what is specific to cache channels.
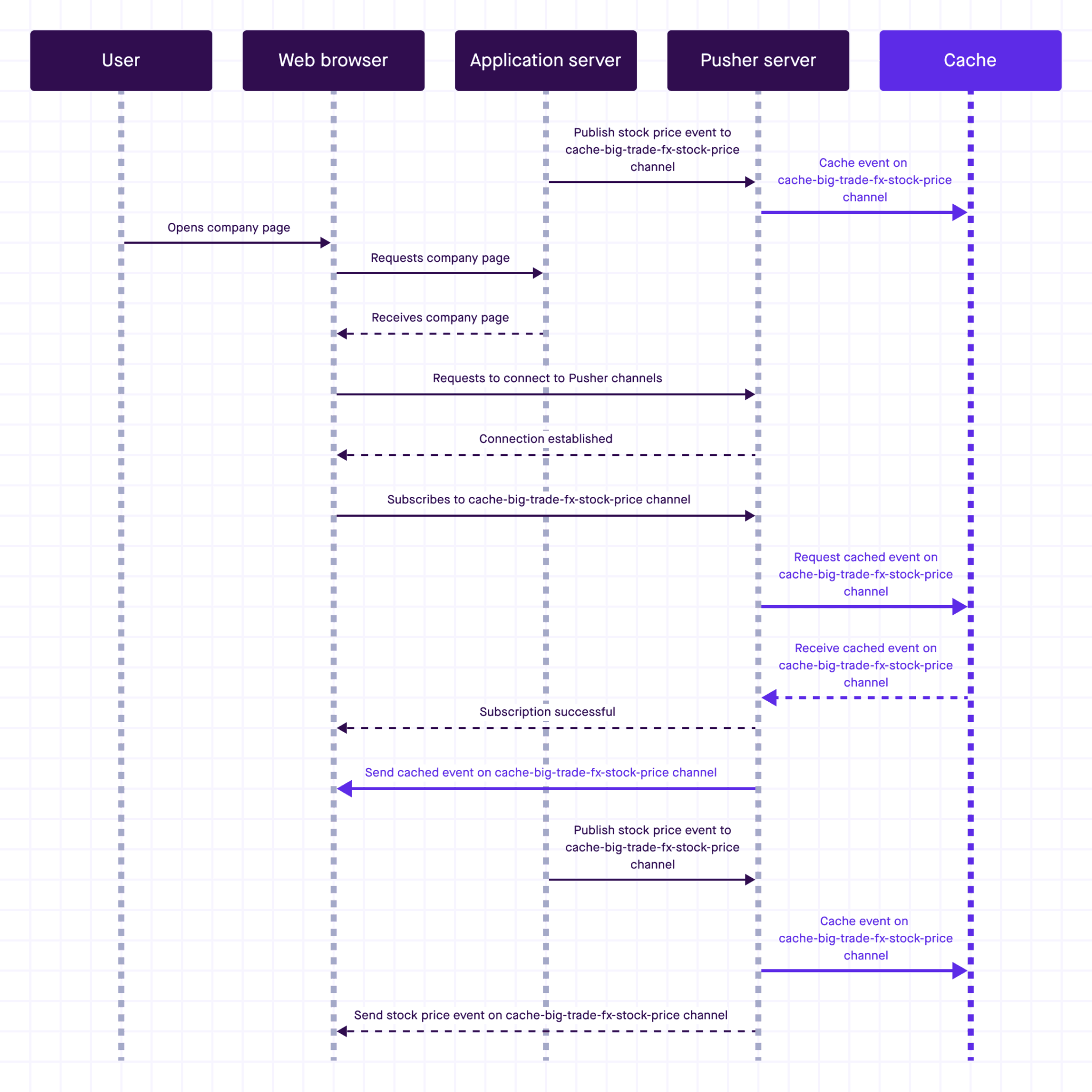
Note that without using a cache channel, there will be a gap between the new subscriber subscribing to the channel and the first time a stock price appears to this new subscriber. This is because it would depend on when the application server receives and publishes a new stock price.
Ease of use with HTTP API for cache channels
Pusher already provides two ways of dealing with the scenario of a user subscribing to a cache channel while the cache is empty. Those are cache_miss events and cache miss webhooks.
The HTTP API integration offers another flexible method of application behavior relevant to the state of the cache. Your application server is now able to retrieve the current value in the cache and define its time to live (TTL) using our HTTP API through our server SDKs.
Here’s an example call using the Pusher node server SDK:
Server side – Node.js
pusher.get({ path: "/channels/cache-big-trade-fx-stock-price", params: {info: "cache"}} });
The result of this call would include a cache field containing either null, if the cache was empty, or an object with the cache data and ttl.
The HTTP API for Cache channels can be used to customize the behavior of your application according to the state of the cache, to optimize initial page rendering, for logging, or for general observability.
More flexibility in accessing cached data
Cache channels are a simple solution to a common set of use cases and make it even easier to adopt Pusher Channels in your realtime app. They allow your application to provide an initial state to any user when they start your application or open your web page. With the HTTP API, you now have more flexibility in how you access the data in the cache from your application server, enabling you to fine-tune the behavior of your application according to the current state of a channel.






© 2026 Pusher Ltd. All rights reserved.
Pusher Limited is a company registered in England and Wales (No. 07489873) whose registered office is at MessageBird UK Limited, 3 More London Riverside, 4th Floor, London, United Kingdom, SE1 2AQ.