- Products

- Developers
- User stories
- Blog
- Pricing

Migrating Channels webhooks from Beanstalkd to Kinesis/SQS
Read about how the Pusher engineering team has been optimising the performance and reliability of the Channels webhooks system using Kinesis and SQS.
Introduction
Here at Pusher we’re in the process of moving some of the services that run Channels from the current EC2/Puppet based setup to Kubernetes.
Although Channels is a very stable platform – almost all corners of the system “just work” – it’s been around for a few years now and the technology landscape has changed a great deal in that time. The migration process has forced us to consider each part of the system and assess whether it’s worth investing time moving it to Kubernetes or whether now would be a good time to invest a little more time improving and modernising things.
Most recently, we considered the system which powers Channels webhooks.
Existing Webhook Architecture
At the heart of the Channels webhooks system is a generic event stream powered by beanstalkd. When certain events occur in Channels, a job containing details of the event is placed on a beanstalkd queue. We refer to this queue as the stream queue.
Jobs from the stream queue are consumed by a “packager” process which identifies the events that should lead to a customer webhook. For each of these events, the process assembles the body/headers/URL the webhook should contain, packages them into another job and places that job on a different beanstalkd queue we call the send_webhook queue.
The send_webhook queue is consumed by a sender process which makes the HTTP request to the customer server.
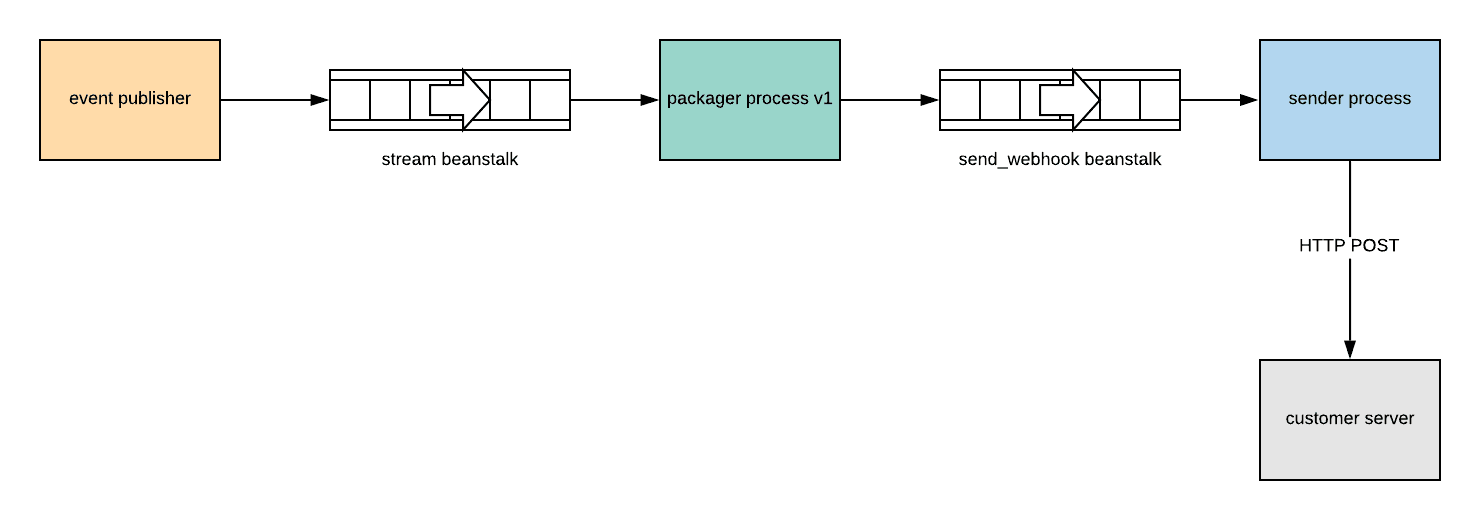
“Packager” Process
In addition to building the webhook job, the packager process has some additional responsibilities.
Debouncing Events
If a user 123 leaves a channel my-channel then immediately rejoins the same channel, two distinct events are added to the event stream. There is little benefit to sending these events to customer, since after both events are applied, the state remains the same (user 123 is in channel my-channel). To reduce load on our customers’ webhook processing servers, when sequences of events like this enter the event stream, we send neither event. This is called debouncing.
The rough process for debouncing works like this:
- An event (
A) which is eligible for debouncing arrives in the event stream. The packager process holds onto it. - If an event (
B) which cancels A arrives in the event stream, the packager process discards eventsAandB - If no event comes along, the packager process sends even
A
Batching Events In order to make fewer HTTP requests to our customers’ servers, we batch similar events into a single HTTP request. Events are stored by the packager process until one of the following occurs:
- The size of the batch reaches
max_batch_size - The time since the first message in the batch reaches
max_batch_delay
At which point the whole batch is sent to the next stage.
Sharding The packager process process is written in EventMachine ruby. This means it’s limited to a single core.
To keep up with the volume of events on larger Channels clusters (60,000-70,000 events/s) we need to deploy multiple instances of the packager process.
However, in order for debouncing to work properly, it’s vital that all events concerning a specific channel are processed by the same packager process. Otherwise, a “debounceable” event and its complement might be processed by different packager processes. In this scenario, neither packager process would know about the job the other was processing and the job would not be debounced.
To ensure events are routed to the appropriate packager process, we divide the event stream into multiple logical “shards”. Each shard of the stream is a different beanstalkd queue (called stream_0, stream_1, etc.). In order to consume from a stream shard, a packager process must obtain a lock.
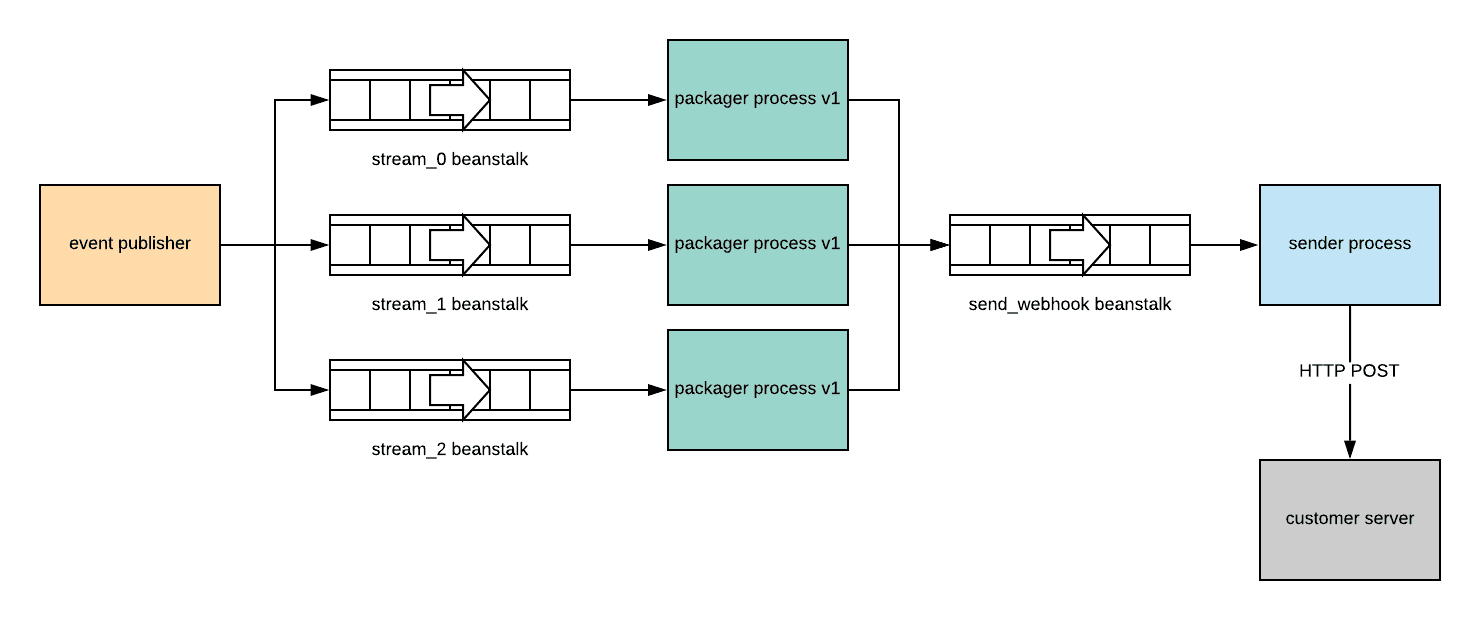
This configuration allows us to divide the workload between multiple packager processes while ensuring that all events concerning a single channel are always processed by the same packager process
Note: We don’t do any sharding of the send_webhook q ueue because the sender process is completely stateless. All of the data it needs to do its work is contained within the jobs it consumes and each job is independent. This means that an arbitrary number of senders can process a single beanstalkd queue without issue.
Problems
This solution has mostly worked well for us. The architecture has some very nice properties (independent scaling) etc. The implementation does have some problems though:
- Operational complexity – we self-host beanstalkd on EC2. Although beanstalkd is a solid piece of software, it requires some expertise to operate and manage, replacing machines running beanstalkd processes can be a little fiddly. In general we prefer to use managed services for parts of our infrastructure that don’t form an important part of our value proposition.
- EventMachine – the packager process is written in ruby EventMachine, the EventMachine ecosystem is stagnating somewhat. We’re trying to move away from EventMachine where it makes sense.
- Shard balancing – The sharding logic is fairly simplistic, it’s possible for a single process to gain the lock for more shards than it can effectively process. This happens rarely but usually results in delayed webhooks and requires manual intervention to rebalance the shards. In addition, adding/removing shards requires fiddly configuration changes. We could improve the packager process but that would involve investing more in our EventMachine code base.
Alternatives
Although the issues with the webhook system were not severely affecting the stability of the platform yet, it was hard to see where a solution to the two most significant problems (operational complexity/EventMachine stagnation) might come from.
Given the investment required to migrate the existing system (and its problems) to Kubernetes we decided it would be prudent to consider improvements before the webhook system started giving us severe problems.
SQS
We’ve had some positive experiences with SQS in the past so this was our first avenue of exploration. SQS seemed like a drop in replacement for the (non-sharded) send_webhook beanstalk.
The stream_<n> beanstalks were trickier though. We considered replicating the architecture of the existing system by creating an SQS queue per shard but this arrangement shared some of the issues of the existing system:
- We’d still need to manage sharding in the EventMachine application layer (and we’d have to add SQS support)
…and created some new ones:
- Resharding would become more awkward since, unlike beanstalkd tubes, SQS queues are not created “on-demand”. To add/remove shards we’d need to provision new queues with terraform aswell as updating the application config.
Kinesis
A Kinesis stream consumed by a Kinesis Client Library (KCL) instance seemed like a much better fit to replace the event stream beanstalks. Kinesis streams are sharded by default and KCL handles things like shard rebalancing and checkpointing.
If we could convert the packager process into a KCL consumer, we could reduce the complexity of the packager process and give it some more favourable properties (automatic lossless resharding, better durability).
Unfortunately KCL is only available as a Java library. While there is a ruby library that interfaces with the KCL multilang daemon we’d still have to run the Java daemon in production which added operational complexity.
While researching Kinesis, we stumbled upon kinsumer, a library which replicates the functionality of KCL in Go. We’re pretty comfortable with Go at pusher and generally favour it when writing new services. Given the suitability of Kinesis for our workload and our general preference for replacing EventMachine services where sensible, it seemed reasonable to re-implement the packager process in Go.
Implementation and Testing
We spent some time reimplementing the functionality of the packager process in a new Go service based on kinsumer, adding Kinesis support to the event stream publishers and SQS support to the sender process.
The initial tests in our staging environment seemed positive. However, most of the issues we experience with Channels happen at scale. It was important to understand how everything stood up to a production workload, without switching everything over to the new system.
Parallel Publishing
During a low traffic period, we configured the event publishers to publish to both the beanstalk queue and the Kinesis stream in parallel.
Although the new packager service was consuming jobs from the Kinesis stream and publishing jobs to the SQS queue, nothing was consuming from the SQS queue. This ensured we weren’t publishing every webhook twice.
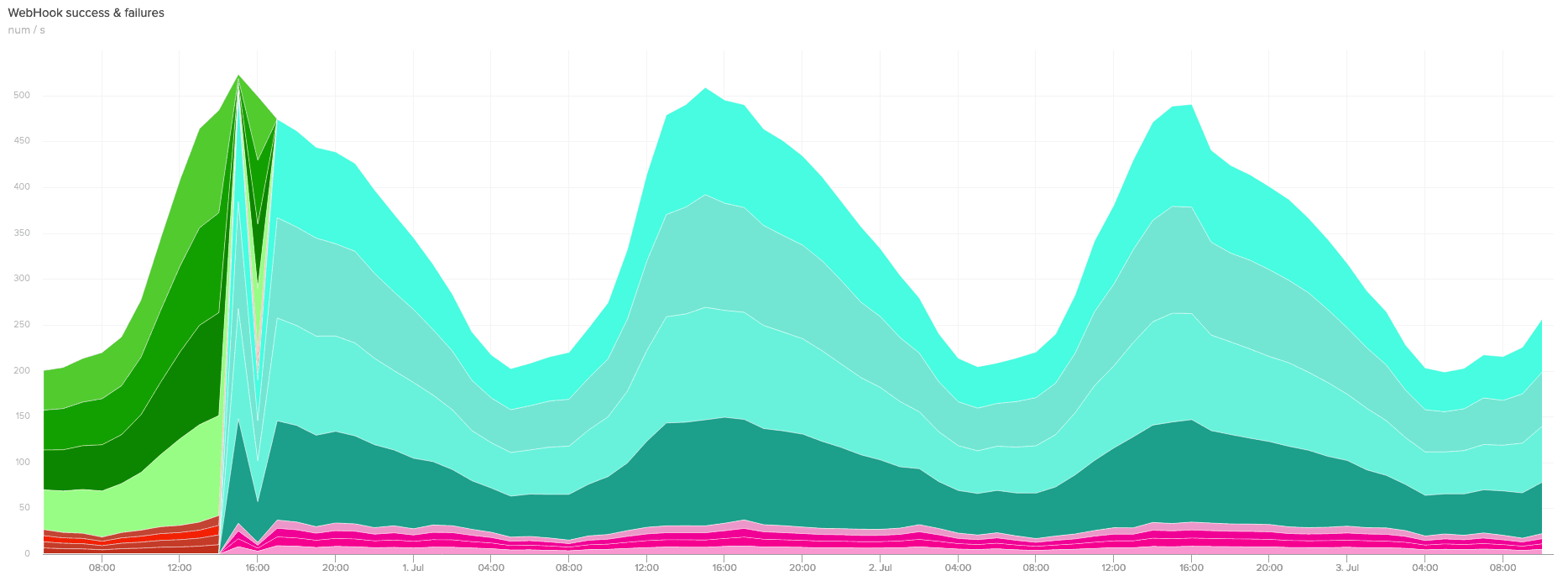
With this configuration, we could compare the metrics reported by the new service with those from the existing service.
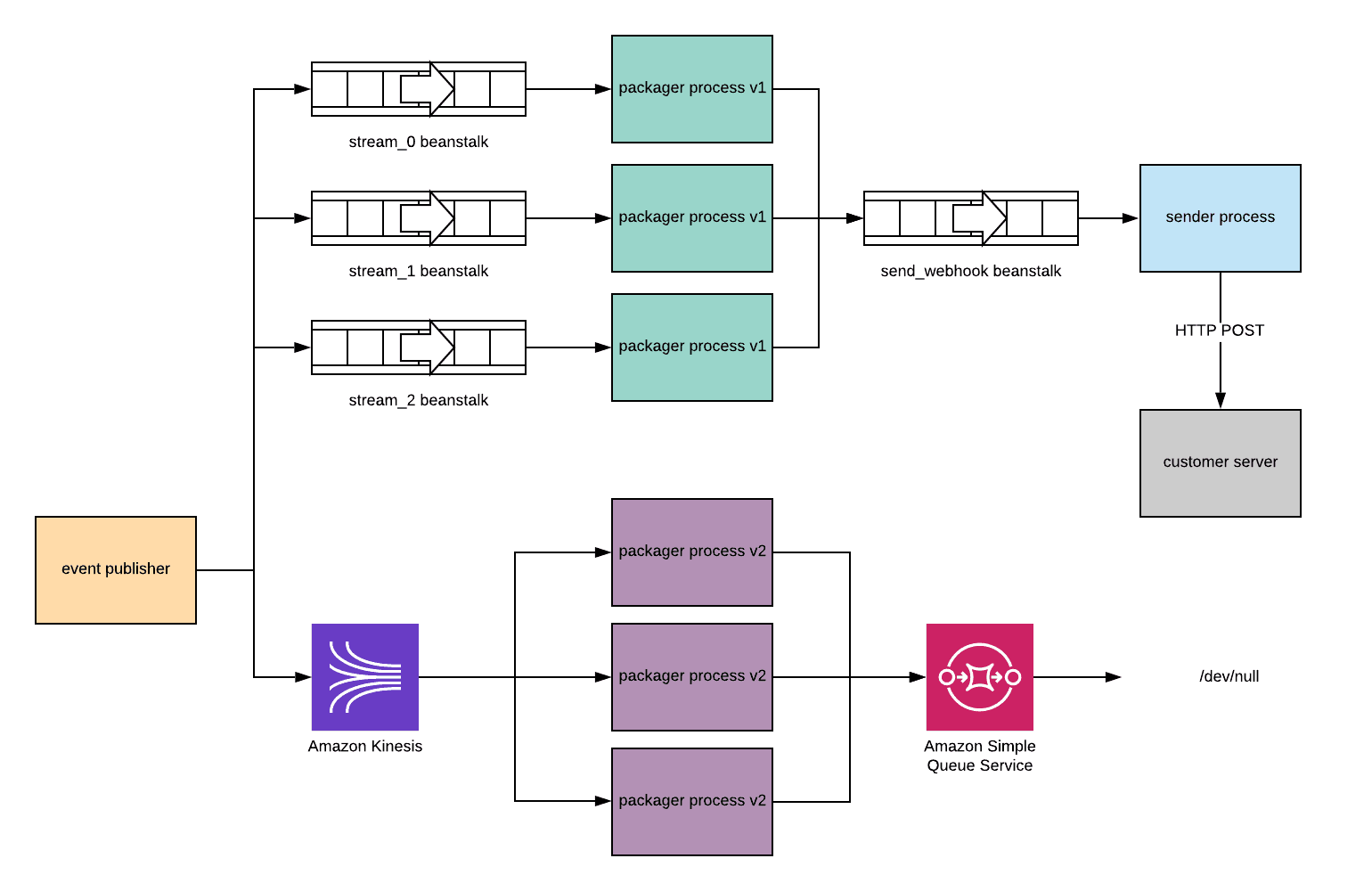
After a while publishing to both queues in parallel, we were confident that the new service was stable at the necessary scale and that it debounced and batched webhooks in broadly the same way as the old system. We restored the cluster back to its starting state (not publishing to Kinesis) and started considering how to go about migrating production traffic.
Migration
As discussed previously, having multiple processes consuming the event stream at the same time, can lead to issues. This made a gradual rollout impossible – in order to migrate, we were going to have to switch everything from the old system to the new system at once.
We started by configuring the sender processes to consume from both the beanstalk queues and the SQS queues. Although the new packager process was running, nothing was being published to Kinesis, so no jobs were being placed in the SQS queues.
In a single stronghold configuration change, we disabled publishing to the beanstalk queue and enabled publishing to Kinesis. All of the publisher processes simultaneously stopped publishing their jobs to beanstalk and started publishing them to Kinesis.
Although this was a nerve-racking moment, it was happily anticlimactic and nobody actually noticed that anything had changed.
Conclusion
At the moment the new webhook system is functionally extremely similar to the old one, it’s just considerably more performant and more reliable. However we’re glad to have removed one more EventMachine service from the system, and we’re glad to not have to worry about replacing machines running beanstalk processes any more!
We’re also really excited to have a generic event-stream in something like Kinesis and are looking forward to using this as a springboard to further improve the Channels webhook system.






© 2026 Pusher Ltd. All rights reserved.
Pusher Limited is a company registered in England and Wales (No. 07489873) whose registered office is at MessageBird UK Limited, 3 More London Riverside, 4th Floor, London, United Kingdom, SE1 2AQ.