- Products

- Developers
- User stories
- Blog
- Pricing

How to build a GraphQL API with the Serverless framework
In this tutorial, we will build a GraphQL API, and deploy it using the Serverless framework for AWS. Use Node.js for the backend, along with AWS' Lambda functions.
Introduction
In a previous article, we explored how to build a serverless REST API using AWS Lambda and the Serverless framework. In this article, we’ll build a different version of that API, providing the same functionality, but through a GraphQL interface instead.
GraphQL is a query language for interacting with APIs. It provides a lot of benefits such as:
- Strong typing. With GraphQL, all fields in the request and response need to conform to a previously declared type. This helps prevent a large class of bugs.
- Client-specified interfaces. The client specifies the fields they wish to retrieve (or update) in the request and the server returns only those fields.
- Retrieving multiple levels of data in a query. With GraphQL, it’s much easier to ask for a user, along with all posts belonging to that user, as well as their comments, in a single query.
With GraphQL, all requests are made to one endpoint. The data to return or operation to perform is determined by the query specified in the request.
Here’s a brief overview of the operations our service will support via GraphQL queries:
- Adding a product to the warehouse.
- Retrieving all products in the warehouse.
- Retrieving a single product.
- Removing a product from the warehouse.
We’ll use AWS DynamoDB as our data store. Let’s go!
Prerequisites
- Node.js v6.10 or later
- An AWS account. You can sign up for a free account here.
Setting up the project
First, install the Serverless CLI:
1npm install -g serverless
Next, we’ll create a new service using the AWS Node.js template. Create a folder to hold your service (I’m calling mine stockup-gql) and run the following command in it:
1serverless create --template aws-nodejs
This will populate the current directory with the starter files needed for the service.
Let’s add our application dependencies before we go on. Run the following command to set up a package.json file in your application directory:
1npm init -y
Then install dependencies by running:
1npm install graphql aws-sdk
Configuring our service
The serverless.yml file acts as a manifest for our service. It contains information that the Serverless CLI will use to configure and deploy our service to AWS. Replace the contents of your serverless.yml file with the following:
1service: stockup-gql 2 3 provider: 4 name: aws 5 runtime: nodejs6.10 6 iamRoleStatements: 7 - Effect: Allow 8 Action: 9 - dynamodb:DescribeTable 10 - dynamodb:Query 11 - dynamodb:Scan 12 - dynamodb:GetItem 13 - dynamodb:PutItem 14 - dynamodb:UpdateItem 15 - dynamodb:DeleteItem 16 Resource: 17 Fn::Join: 18 - "" 19 - - "arn:aws:dynamodb:*:*:table/" 20 - Ref: ProductsGqlDynamoDbTable 21 22 functions: 23 queryProducts: 24 handler: handler.queryProducts 25 events: 26 - http: 27 path: products 28 method: post 29 cors: true 30 environment: 31 TABLE_NAME: products-gql 32 33 resources: 34 Resources: 35 ProductsGqlDynamoDbTable: 36 Type: AWS::DynamoDB::Table 37 Properties: 38 TableName: products-gql 39 AttributeDefinitions: 40 - AttributeName: id 41 AttributeType: S 42 KeySchema: 43 - AttributeName: id 44 KeyType: HASH 45 ProvisionedThroughput: 46 ReadCapacityUnits: 1 47 WriteCapacityUnits: 1
A brief explanation of this file:
- The
servicekey contains the name of our service (“stockup-gql”) - The
providerkey is where we specify the name of the provider we’re using (AWS) and configurations specific to it. Here, we’ve specified two configurations:- The
runtimeenvironment that our service will run in (Node.js) - The IAM (Identity Access Management) role that our functions will run under. Our functions need to read from and write to our DynamoDB permissions, so we’ve added the necessary permissions to the IAM role.
- The
- The
functionskey holds the functions provided by our service, the events (API calls) that should trigger them, and their handlers (we’ll write the code for the handlers soon). We have just one function, the GraphQL endpoint we’ve calledqueryProducts. For this function, we specify the events that should trigger it (a HTTP request) as well as an environment variable to pass to it (the database table name). - The
resourceskey contains all necessary configuration for AWS resources our service will access. In our case, we’ve configured the DynamoDB resource by specifying the name of the table we’ll be interacting with (products). DynamoDB is schemaless but requires you to declare the primary key for each table, so we’ve defined this in ourAttributeDefinitionsandKeySchema. We’re using theid, a string, as our primary key.
Writing our application logic
First, let’s write the code that interacts with our database directly. Create a directory called resolvers. We’ll export these functions and provide them to GraphQL for handling the query.
Create a file called create.js in the resolvers directory with the following code:
1'use strict'; 2 3 const AWS = require('aws-sdk'); 4 const dynamoDb = new AWS.DynamoDB.DocumentClient(); 5 const uuid = require('uuid'); 6 7 module.exports = (data) => { 8 const params = { 9 TableName: process.env.TABLE_NAME, 10 Item: { 11 name: data.name, 12 quantity: data.quantity, 13 id: uuid.v1(), 14 addedAt: Date.now(), 15 } 16 }; 17 return dynamoDb.put(params).promise() 18 .then(result => params.Item) 19 };
In this file, we’re exporting a function that takes in the product data (sent by the user in the body of the request). Our function then creates a new product in the database, returning the result via a Promise.
Next up is our list function (resolvers/list.js). We don’t need any parameters for this. We call the DynamoDB scan command to get all the products:
1'use strict'; 2 3 const AWS = require('aws-sdk'); 4 const dynamoDb = new AWS.DynamoDB.DocumentClient(); 5 6 module.exports = () => dynamoDb.scan({ TableName: process.env.TABLE_NAME }) 7 .promise() 8 .then(r => r.Items);
Our view function (resolvers/view.js) takes in the product ID and returns the corresponding product using dynamoDb.get:
1'use strict'; 2 3 const AWS = require('aws-sdk'); 4 const dynamoDb = new AWS.DynamoDB.DocumentClient(); 5 6 module.exports = (id) => { 7 const params = { 8 TableName: process.env.TABLE_NAME, 9 Key: { id } 10 }; 11 return dynamoDb.get(params).promise() 12 .then(r => r.Item); 13 };
And our remove function (resolvers/remove.js) also takes a product ID, then uses the delete command to remove the corresponding product:
1'use strict'; 2 3 const AWS = require('aws-sdk'); 4 const dynamoDb = new AWS.DynamoDB.DocumentClient(); 5 6 module.exports = (id) => { 7 const params = { 8 TableName: process.env.TABLE_NAME, 9 Key: { id } 10 }; 11 return dynamoDb.delete(params).promise() 12 };
All good.
Defining our schema
GraphQL is a strongly typed query language. This means we have to define our schema beforehand. Our schema will specify the possible operations that can be performed on our data, as well as type definitions for our data. Our schema will also map resolvers (the functions we wrote in the last section) to these operations, allowing GraphQL to build a response to a query.
Let’s write our schema now. Create a file called schema.js in your project’s root directory with the following content:
1'use strict'; 2 3 const { 4 GraphQLSchema, 5 GraphQLObjectType, 6 GraphQLString, 7 GraphQLInt, 8 GraphQLList, 9 GraphQLNonNull, 10 GraphQLBoolean 11 } = require('graphql'); 12 const addProduct = require('./resolvers/create'); 13 const viewProduct = require('./resolvers/view'); 14 const listProducts = require('./resolvers/list'); 15 const removeProduct = require('./resolvers/remove'); 16 17 const productType = new GraphQLObjectType({ 18 name: 'Product', 19 fields: { 20 id: { type: new GraphQLNonNull(GraphQLString) }, 21 name: { type: new GraphQLNonNull(GraphQLString) }, 22 quantity: { type: new GraphQLNonNull(GraphQLInt) }, 23 addedAt: { type: new GraphQLNonNull(GraphQLString) }, 24 } 25 }); 26 27 28 const schema = new GraphQLSchema({ 29 query: new GraphQLObjectType({ 30 name: 'Query', 31 fields: { 32 listProducts: { 33 type: new GraphQLList(productType), 34 resolve: (parent, args) => listProducts() 35 }, 36 viewProduct: { 37 args: { 38 id: { type: new GraphQLNonNull(GraphQLString) } 39 }, 40 type: productType, 41 resolve: (parent, args) => viewProduct(args.id) 42 } 43 } 44 }), 45 46 mutation: new GraphQLObjectType({ 47 name: 'Mutation', 48 fields: { 49 createProduct: { 50 args: { 51 name: { type: new GraphQLNonNull(GraphQLString) }, 52 quantity: { type: new GraphQLNonNull(GraphQLInt) } 53 }, 54 type: productType, 55 resolve: (parent, args) => addProduct(args) 56 }, 57 removeProduct: { 58 args: { 59 id: { type: new GraphQLNonNull(GraphQLString) } 60 }, 61 type: GraphQLBoolean, 62 resolve: (parent, args) => removeProduct(args.id) 63 }, 64 } 65 }) 66 }); 67 68 module.exports = schema;
Here’s an explanation of the code in this file:
- The first thing we define is a
Producttype. This type represents a single product in our database. For each product, we’ll store the name, the quantity, a timestamp marking when it was added, and a unique ID. We’ll need this type when constructing our schema. - Next, we define our schema. GraphQL supports two kinds of operations: queries and mutations. Queries are used for fetching data, while mutations are used for making changes to data (for instance, creating or removing a product), These operations are also defined as types in the
queryandmutationfields of ourschemaobject. Thefieldvalues of thequeryandmutationobjects contain the queries and mutations we’re supporting, and we call our resolvers in theresolvefunction in order to obtain the result.
Bringing it all together
Now we need to update our handler.js to pass the input request to GraphQL and return the result. This is actually pretty easy to do. Replace the code in your handler.js with the following:
1'use strict'; 2 3 const { graphql } = require('graphql'); 4 const schema = require('./schema'); 5 6 module.exports.queryProducts = (event, context, callback) => { 7 graphql(schema, event.body) 8 .then(result => callback(null, {statusCode: 200, body: JSON.stringify(result)})) 9 .catch(callback); 10 };
The first argument we pass to the graphql function is the schema we’ve built. This tells GraphQL what to validate against and how to resolve the request into our application logic. The second parameter is the request which we are receiving as the body of the POST request.
Deploying and querying our API
Note: you’ll need to first configure the Serverless CLI with your AWS credentials. Serverless has published a guide on that (in video and text formats).
Run this command to deploy your service to AWS:
1serverless deploy
When the command is done, you should see output like this:
1Service Information 2 service: stockup-gql 3 stage: dev 4 region: us-east-1 5 stack: stockup-gql-dev 6 api keys: 7 None 8 endpoints: 9 POST - https://xxxxxx.execute-api.us-east-1.amazonaws.com/dev/products 10 functions: 11 queryProducts: stockup-gql-dev-queryProducts
Copy the URL shown under the endpoints section. This is where we’ll send our API queries.
Now let’s test the API. Open up Postman or whatever API testing tool you use. First, we’ll try to create a new product. Make a POST request to the API URL with the body contents as follows:
1mutation { 2 createProduct (name: "Productine", quantity: 2) { 3 id, 4 name, 5 quantity, 6 addedAt 7 } 8 }
Here we’re running the createProduct mutation, providing a name and quantity as we required in the args field of the mutation in our schema. The attributes listed in braces represent the fields we wish to see when the result is returned to us.
When you run the request, you should get a response like this:
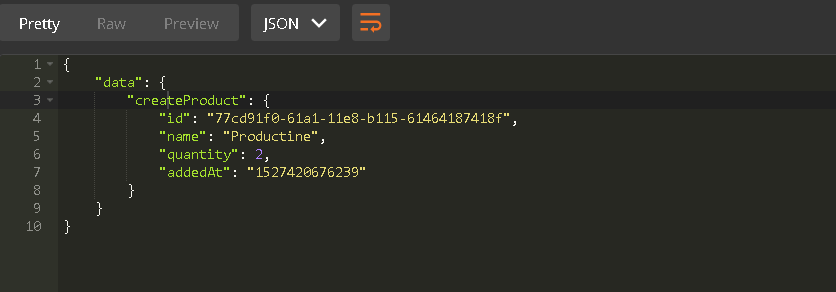
Let’s try viewing the product we just created. Change the contents of your request to the following (replace <id> with the ID of the product you just created):
1query { 2 viewProduct (id: "<id>") { 3 name, 4 addedAt 5 } 6 }
Note that now we’re only asking for the name and addedAt fields in the response, so those are the only fields that will be present in it. Here’s what your response should look like when you run this:
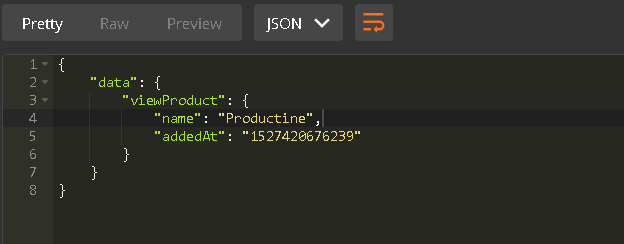
Similarly, we can retrieve all products with this query:
1query { 2 listProducts { 3 name, 4 addedAt 5 } 6 }
And remove the product we just created using this:
1mutation { 2 removeProduct (id: "<id>") 3 }
Note that in our schema we defined this mutation to return a boolean value, so we can’t request for any fields on the response.
Play around with your API and watch what happens when you omit some required arguments (such as not passing an ID to viewProduct) or request a nonexistent field in the response, or try to perform a nonexistent query.
Conclusion
In this article, we’ve built a GraphQL API hosted on AWS Lambda. We’ve seen how GraphQL helps us provide a consistent, type-safe and powerful interface to our API, and automatically validate all incoming requests. In a large app, these are very useful features to ensure consistent performance.
Here are a few more resources for further research:
You can also check out the full source code of our app on GitHub.






© 2026 Pusher Ltd. All rights reserved.
Pusher Limited is a company registered in England and Wales (No. 07489873) whose registered office is at MessageBird UK Limited, 3 More London Riverside, 4th Floor, London, United Kingdom, SE1 2AQ.