- Products

- Developers
- User stories
- Blog
- Pricing

Getting up and running with GraphQL
In this tutorial, you will learn what GraphQL is, its features and concepts. Finally, learn how to build a simple GraphQL server.
Introduction
The adoption of GraphQL is increasing as companies like Facebook, GitHub and Pinterest use it to power their applications, and many developers are already moving to (or at least leaning towards) GraphQL because of the great features it introduces. Today, I will be getting you up to speed with GraphQL.
This article is divided into two parts: in the first part we’ll look at what GraphQL is, the features it introduces, and the GraphQL concepts in general, then in the second part we’ll get our hands dirty by building a simple GraphQL server.
What Is GraphQL?
Back in 2012, Facebook created GraphQL as an internal project to help power their mobile applications. After using it in production for some years, they decided to release it to the public and open sourced it in 2015. So, what is GraphQL?
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. GraphQL provides a complete and understandable description of the data in your API, gives clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools.
http://graphql.org
In other words, GraphQL is a declarative data fetching specification and query language. It is meant to provide a common interface between the client and the server for data fetching and manipulations.
From the name GraphQL, you might be tempted to think that GraphQL is related to graph database or SQL. In fact, GraphQL has nothing to do with data storage; nor does it have anything to do with graph databases.
To further understand what GraphQL is, let’s take a look at some of its features:
- Declarative: With GraphQL, what you queried is what you get, nothing more and nothing less.
- Hierarchical: GraphQL naturally follows relationships between objects. With a single request, we can get an object and its related objects. For instance, with a single request, we can get an
Authoralong with thePostshe has created, and in turn get theCommentson each of the posts. - Strongly-typed: With GraphQL type system, we can describe possible data that can be queried on the server and rest assured that the response we’ll get from a server is in line with what was specified in the query.
- Not Language specific:** GraphQL is not tied to a specific programming language as there are several implementations of the GraphQL specification in different languages.
- Compatible with any backend: GraphQL is not limited by a specific data storage; you can use your existing data and code or even connect to third-party APIs.
- Introspective: With this, a GraphQL server can be queried for details about the schema.
In addition to these features, GraphQL is easy to use as it has a JSON like syntax and also provides lots of performance benefits.
Having seen what GraphQL is and some of its features, let’s dive deeper. We’ll see the syntax and the operations that can be performed with GraphQL. GraphQL operations can be either read or write operations.
Query
Queries are used to perform read operations, that is, fetching data from the server. Queries define the actions we can perform on the schema (more on schema shortly). Below is a simple GraphQL query and its corresponding response:
1# Basic GraphQL Query 2 3 { 4 author { 5 name 6 posts { 7 title 8 } 9 } 10 }
1# Basic GraphQL Query Response 2 3 { 4 "data": { 5 "author": { 6 "name": "Chimezie Enyinnaya", 7 "posts": [ 8 { 9 "title": "How to build a collaborative note app using Laravel" 10 }, 11 { 12 "title": "Event-Driven Laravel Applications" 13 } 14 ] 15 } 16 } 17 }
This is a simple query that gets the name of an author and the posts created by the author. Notice that the query and the response have the same structure. Also, the response contains an array of posts created by the author and we were able to achieve this with a single request.
Let’s go over and explain the components of a GraphQL query.
In the query above, we omitted the query keyword. If an operation doesn’t include a type, by default GraphQl will treat such operation as a query. A query can have a name. Though the name is optional, it makes it easy to identify what a particular query does. In production applications, it is recommended to use the query keyword and name your queries so as to make your code easy to understand.
1query GetAuthor { 2 author { 3 # The name of the author 4 name 5 } 6 }
We have given our query a name GetAuthor which is quite descriptive. Queries can also contain comments. Each line of comment must start with the # sign.
Fields
Fields are basically parts of an object we want to retrieve from a server. In the query above, name is a field on the author object.
Arguments
Just like functions in programming languages can accept arguments, a query can accept arguments. Arguments can be either optional or required. So we can rewrite our query to accept the ID of the author as an argument:
1{ 2 author(id: 5) { 3 name 4 } 5 }
Heads up: GraphQL requires strings to be wrapped in double quotes.
Variables
In addition to arguments, a query can also have variables which make a query more dynamic instead of hard coding the arguments. Variables are prefixed with the $ sign followed by their type.
1query GetAuthor($authorID: Int!) { 2 author(id: $authorID) { 3 name 4 } 5 }
Variables can also have default values:
1query GetAuthor($authorID: Int! = 5) { 2 author(id: $authorID) { 3 name 4 } 5 }
Like arguments, variables can be either optional or required. In our example, $authorID is required because of the ! symbol (more on this under schema) included in the variable definition.
Aliases
With the above query, let’s assume we want to get authors with IDs 5 and 7 respectively. We might be tempted to do something like this:
1{ 2 author(id: 5) { 3 name 4 } 5 author(id: 7) { 6 name 7 } 8 }
This will throw an error as there would be conflict between the two name fields. To resolve this, we’ll use aliases. With aliases, we can give the fields customised names and request data from the same field with different arguments.
1{ 2 chimezie: author(id: 5) { 3 name 4 } 5 neo: author(id: 7) { 6 name 7 } 8 }
And the response will be something similar to:
1# Response 2 3 { 4 "data": { 5 "chimezie": { 6 "name": "Chimezie Enyinnaya" 7 }, 8 "neo": { 9 "name": "Neo Ighodaro" 10 } 11 } 12 }
Fragments
Fragments are reusable set of fields that can be included in queries as needed. Assuming we need to fetch a twitterHandle field on the author object, we can easily do that with:
1{ 2 chimezie: author(id: 5) { 3 name 4 twitterHandle 5 } 6 neo: author(id: 7) { 7 name 8 twitterHandle 9 } 10 }
But what about if we want to pull more fields? This can quickly become repetitive and redundant. That’s where fragments comes into play. Below is how we would solve the above situation using fragments:
1{ 2 chimezie: author(id: 5) { 3 ...authorDetails 4 } 5 neo: author(id: 7) { 6 ...authorDetails 7 } 8 } 9 10 fragment authorDetails on Author { 11 name 12 twitterHandle 13 }
Now we will only need to add our fields in one place.
Directives
Directives provide a way to dynamically change the structure and shape of our queries using variables. As of this post, the GraphQL specification includes exactly two directives:
@includewill include a field or fragment only when theifargument istrue@skipwill skip a field or fragment when theifargument istrue
The two directives both accept a Boolean (true or false) as arguments.
1query GetAuthor($authorID: Int!, $notOnTwitter: Boolean!, $hasPosts: Post) { 2 author(id: $authorID) { 3 name 4 twitterHandle @skip(if: $notOnTwitter) 5 posts @include(if: $hasPosts) { 6 title 7 } 8 } 9 }
The server will not return a response with the author’s Twitter handle if $notOnTwitter is true. Also, the server will return a response with the author’s post only if the author has written some posts, that is, $hasPosts is true.
Mutation
In a typical API usage, there are scenarios where we would want to modify the data on the server. That’s where mutations come into play. Mutations are used to perform write operations. By using mutations, we can make a request to a server to amend or update specific data, and we would get a response that contains the updates made. It has a similar syntax to the query operation with a slight difference.
1mutation UpdateAuthorDetails($authorID: Int!, $twitterHandle: String!) { 2 updateAuthor(id: $authorID, twitterHandle: $twitterHandle) { 3 twitterHandle 4 } 5 }
We send data as a payload in a mutation. For our example mutation, we could send the following data as payload:
1# Update data 2 3 { 4 "authorID": 5, 5 "twitterHandle": "ammezie" 6 }
And we’ll get the following response after the update has been made on the server:
1# Response after update 2 3 { 4 "data": { 5 "id": 5, 6 "twitterHandle": "ammezie" 7 } 8 }
Notice the response contains the newly updated data.
Just like queries, mutations can also accepts multiple fields. An important distinction between mutations and queries is that mutations are executed serially in order to ensure data integrity, whereas queries are executed in parallel.
Schemas
Schemas describe how data are shaped and what data on the server can be queried. Schemas provide object types used in your data. GraphQL schemas are strongly typed, hence all the object defined in a schema must have types. Types allow the GraphQL server to determine whether a query is valid or not at runtime. Schemas can be of two types: Query and Mutation.
Schemas are constructed using what is called GraphQL schema language, which is quite similar to the query language we saw in the previous sections. Below is a sample GraphQL schema:
1type Author { 2 name: String! 3 posts: [Post] 4 }
The above schema defines an Author object type with two fields (name and posts). This means that we can only use name and posts fields on any GraphQL query operation on Author. The fields on an object types can be optional or required. The name is required because of the ! symbol after it type name.
Arguments
Fields in a schema can accept arguments. These arguments can either be optional or required. Required arguments are denoted with the ! symbol:
1type Post { 2 allowComments(comments: Boolean!) 3 }
Scalar Types
Out of the box, GraphQL comes with the following scalar types:
Int: a signed 32‐bit integerFloat: a signed double-precision floating-point valueString: A UTF‐8 character sequenceBoolean:trueorfalseID: represents a unique identifier
Fields defined as one of the scalar types cannot have fields of their own. We could also specify custom scalar types using the scalar keyword. For example, we could define a Date type:
1scalar Date
Enumeration types
Also called Enums, are a special kind of scalar that is restricted to a particular set of allowed values. With Enums, we can:
- Validate that any arguments of this type are one of the allowed values
- Communicate through the type system that a field will always be one of a finite set of values
Enums are defined with the enum keyword:
1enum Media { 2 Image 3 Video 4 }
Input types
Input types are valuable in the case of mutations, where we might want to pass in a whole object to be created. In the GraphQL schema language, input types look exactly the same as regular object types, but with the keyword input instead of type. The input type is defined as below:
1# Input Type 2 3 input CommentInput { 4 body: String! 5 }
Let’s Get Practical
Enough of the theory, let’s put what we’ve learned so far into practice. We’ll be building a simple task manager GraphQL server with Node.js. Like I said, it is going to be simple but it will cover most of the concepts we learned above and help solidify our understanding of them. Below is a demo of what we’ll be building:
The complete code is available on GitHub
So let’s get started already.
Setting Up Node.js Server
We’ll be using Express as our Node.js framework. Initialize a new Node.js project by using the following command:
1mkdir graphql-tasks-server 2 cd graphql-tasks-server 3 npm init -y 4 5I named the demo `graphql-tasks-server`, but feel free to call it whatever you like. We should have a `package.json` in the project directory. Next, we’ll install Express and some other dependencies that our app will need: 6 7``` language-javascript 8 npm install express body-parser apollo-server-express graphql graphql-tools lodash --save
- Express: Node.js framework.
- Body-parser: Node.js body parsing middleware.
- Apollo-server-express: Apollo GraphQL server for Express.
- Graphql: a reference implementation of GraphQL for JavaScript
- Graphql-tools: an npm package and an opinionated structure for how to build a GraphQL schema and resolvers in JavaScript.
- Lodash: a modern JavaScript utility library delivering modularity, performance & extras.
Having installed our dependencies, let’s start writing some code. We’ll create a src directory which will contain all the code we’ll be writing. Within the src directory, create schema and data directory respectively. The schema directory will contain our schemas and resolvers, while the data directory will contain the sample data we’ll be using for the purpose of this tutorial. Within the schema directory, create index.js and resolvers.js files. Within the data directory, create a data.js file. Lastly, create a server.js file directly in the src directory. We should now have a structure like this:
Open src/server.js and add the code below into it:
1// src/server.js 2 3 const express = require('express'); 4 const bodyParser = require('body-parser'); 5 const { graphqlExpress, graphiqlExpress } = require('apollo-server-express'); 6 const schema = require('./schema/index'); 7 8 const PORT = 3000; 9 10 const app = express(); 11 12 // Graphql 13 app.use('/graphql', bodyParser.json(), graphqlExpress({ schema })); 14 15 // Graphiql 16 app.use('/graphiql', graphiqlExpress({ endpointURL: 'graphql' })); 17 18 app.listen(PORT, () => console.log(`GraphiQL is running on http://localhost:${PORT}/graphiql`));
We pulled in our dependencies (express, body-parser and apollo-server-express) and also our schema (which we’ll create shortly). We have two endpoints: /graphql and /graphiql. The first endpoint is the main endpoint which our GraphQL requests to the server will be made to. We add to it the body-parser middleware as well as Apollo server. Apollo server takes an object as its single argument. In our case, the object contains one item which is our GraphQL schema. The second endpoint is GraphiQL; an in-browser IDE for exploring GraphQL which we’ll be using to test our GraphQL server. Lastly, we start up a Node.js server.
That’s all we have to do to create our Node.js server.
Building The Schema
Let’s move on to create our schemas and their resolvers. Open src/schema/index.js and add the code below into it:
1// src/schema/index.js 2 3 const { makeExecutableSchema } = require('graphql-tools'); 4 const resolvers = require('./resolvers'); 5 6 const typeDefs = ` 7 type Project { 8 id: Int! 9 name: String! 10 tasks: [Task] 11 } 12 type Task { 13 id: Int! 14 title: String! 15 project: Project 16 completed: Boolean! 17 } 18 type Query { 19 projectByName(name: String!): Project 20 fetchTasks: [Task] 21 getTask(id: Int!): Task 22 } 23 type Mutation { 24 markAsCompleted(taskID: Int!): Task 25 } 26 `; 27 28 module.exports = makeExecutableSchema({ typeDefs, resolvers });
First, we reference graphql-tools which will be used to build our schema and reference our resolvers (which we’ll create shortly). We define the schema for our app, we have Project and Task types. A project is something or a goal we’re trying to accomplish, while a task is a small thing which when done will help us to accomplish or goal or project. A project has three fields: id, name and tasks. Both the id and title fields are required fields. The tasks field is a collection of tasks from the Task type. A task has four fields: id, title, project and completed. Again, both the id and title fields are required fields. The project field signifies the Project a task belongs to. The completed field which can be either true or false, indicating whether a task is completed or not. Basically, a project can have many tasks and each task must belong to a project.
Next, we define some queries we’d like to run. projectByName takes the name of a project as an argument, gets a project by the name supplied and returns a single project. fetchTasks fetches all the tasks created and returns a collection of tasks, and getTasks takes the id of a task as an argument, gets a task by the id supplied and returns a single task.
We also define a mutation markAsCompleted which we’ll use to change the status of a task and hence mark the task as completed. It takes the id of the task as an argument and it will return the task after the update has been made. Finally, we use makeExecutableSchema to build our schema, passing to it our schema and the resolvers.
Writing Resolvers
Now we define our resolvers. A resolver is a function that defines how a field in a schema is executed.
Tip: GraphQL resolvers can also return Promises.
Open src/schema/resolvers.js and add the code below into it:
1// src/schema/resolvers.js 2 3 const _ = require('lodash'); 4 5 // Sample data 6 const { projects, tasks } = require('./../data/data'); 7 8 const resolvers = { 9 Query: { 10 // Get a project by name 11 projectByName: (root, { name }) => _.find(projects, { name: name }), 12 13 // Fetch all tasks 14 fetchTasks: () => tasks, 15 16 // Get a task by ID 17 getTask: (root, { id }) => _.find(tasks, { id: id }), 18 19 }, 20 Mutation: { 21 // Mark a task as completed 22 markAsCompleted: (root, { taskID }) => { 23 const task = _.find(tasks, { id: taskID }); 24 25 // Throw error if the task doesn't exist 26 if (!task) { 27 throw new Error(`Couldn't find the task with id ${taskID}`); 28 } 29 30 // Throw error if task is already completed 31 if (task.completed === true) { 32 throw new Error(`Task with id ${taskID} is already completed`); 33 } 34 35 task.completed = true; 36 37 return task; 38 } 39 }, 40 Project: { 41 tasks: (project) => _.filter(tasks, { projectID: project.id }) 42 }, 43 Task: { 44 project: (task) => _.find(projects, { id: task.projectID }) 45 } 46 }; 47 48 module.exports = resolvers;
We reference both lodash and our sample data. Using lodash’s find(), we define functions to execute our queries: projectByName and getTask respectively. For fetchTasks, we simply return the array of tasks. For the markAsCompleted mutation, we first get the task by its id, then throw an error if the task doesn’t exist. We also throw an appropriate error if the task is already completed. If the task exists and is not already completed, we set it as true (that is completed) and return the task.
Since we have tasks and project as fields in our schema, we need to also define functions to execute them respectively. To get the tasks of a project, we use lodash’s filter(), which filters the tasks array and returns a new array containing only the tasks where their projectID equals the supplied project id. Lastly, to get the project a task belongs to, we use lodash’s find() which will return a project with the supplied task projectID.
Add Sample Data
We are almost done with our GraphQL server, we just need to add some sample data to test with. So, open src/data/data.js and add code below into it:
1// src/data/data.js 2 3 const projects = [ 4 { id: 1, name: 'Learn React Native' }, 5 { id: 2, name: 'Workout' }, 6 ]; 7 8 const tasks = [ 9 { id: 1, title: 'Install Node', completed: true, projectID: 1 }, 10 { id: 2, title: 'Install React Native CLI:', completed: false, projectID: 1 }, 11 { id: 3, title: 'Install Xcode', completed: false, projectID: 1 }, 12 { id: 4, title: 'Morning Jog', completed: true, projectID: 2 }, 13 { id: 5, title: 'Visit the gym', completed: false, projectID: 2 } 14 ]; 15 16 module.exports = { projects, tasks };
It’s now time to test our GraphQL server, using GraphiQL. Start up our Express server by executing the command below:
1node src/server.js
The server should be running now and GraphiQL can be accessed through http://localhost:3000/graphiql. Go on and try it out with the query below:
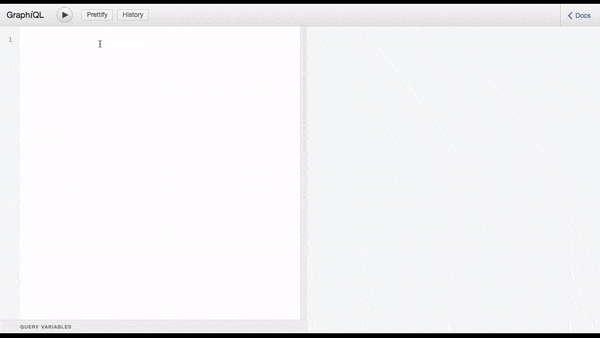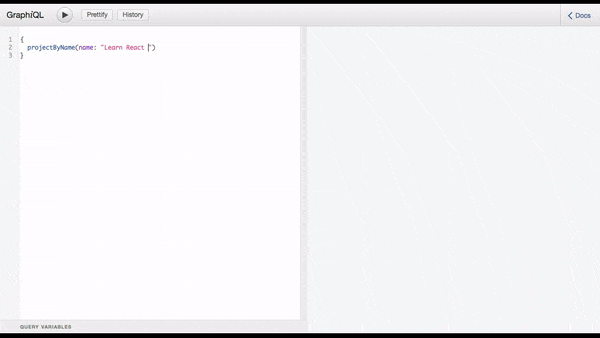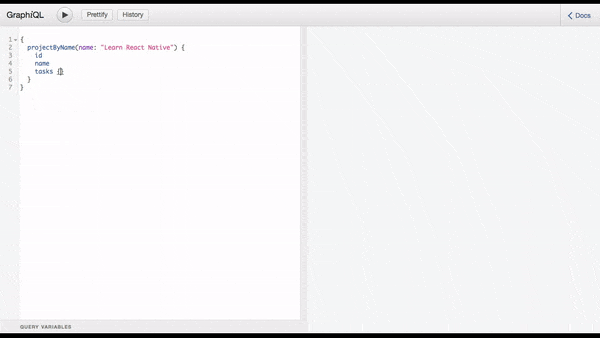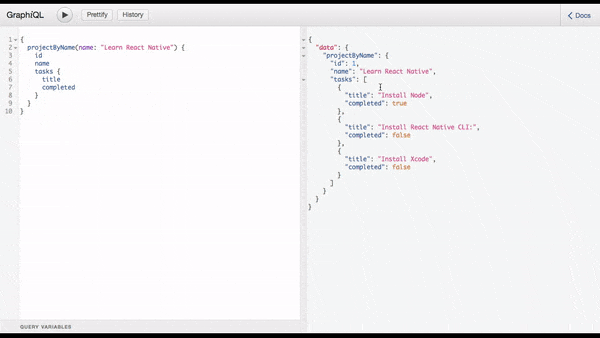
1{ 2 projectByName(name: "Learn React Native") { 3 id 4 name 5 tasks { 6 title 7 completed 8 } 9 } 10 }
You should get a response like the demo below:
Conclusion
We have seen what GraphQL is, the features it introduces and explained some of its concepts. We’ve also put all those into practice by building a simple GraphQL server. Obviously, there are some things I left out as this post is meant to be an overview of GraphQL. To learn more about GraphQL, check out the official documentation and also do check out the GraphQL specifications. You can also drop your questions and comments below.






© 2025 Pusher Ltd. All rights reserved.
Pusher Limited is a company registered in England and Wales (No. 07489873) whose registered office is at MessageBird UK Limited, 3 More London Riverside, 4th Floor, London, United Kingdom, SE1 2AQ.