- Products

- Developers
- User stories
- Blog
- Pricing

Don't Repeat your Mistakes: Conducting Post-mortems
If you don’t have a process for doing post-mortems after incidents, you probably should invest time in building one.
Introduction
We’ve invested a lot of time and thought into the ways that we can reduce risks to the system, and avoid disrupting the thousands of applications that rely on us. However, mistakes and accidents do occasionally happen. If you don’t have a process for doing post-mortems after incidents, you probably should invest time in building one.
While you can prepare for as many eventualities as you can think of, an effective operations team also needs to retrospect on things that went wrong, and work out how to prevent them happening again.
What happens when a bad thing occurs?
Downtime affects our customers pretty badly in Pusher – we have to keep disruption to a minimum. A critical incident generally looks like this:
- An alert is triggered
- Someone looks at the issue
- If necessary, other people are roped in
- We chat in IRC while we investigate and fix
- An ”incident commander” keeps our status page up to date and chats to users
- We fix the issue and go to bed
However, this is just the start of the process for us. Any disruption is so unacceptable that we need to work out why it happened and prevent it from happening in future.
Being systematic about your post-mortems
Learning from mistakes is something that’s often quite difficult to do. Without a framework to help you do it consistently, it can be haphazard and important details can be overlooked or forgotten.
After trying other options, (such as adding pages to our wiki), we opted to write a small application that would help us maintain consistency of reports.
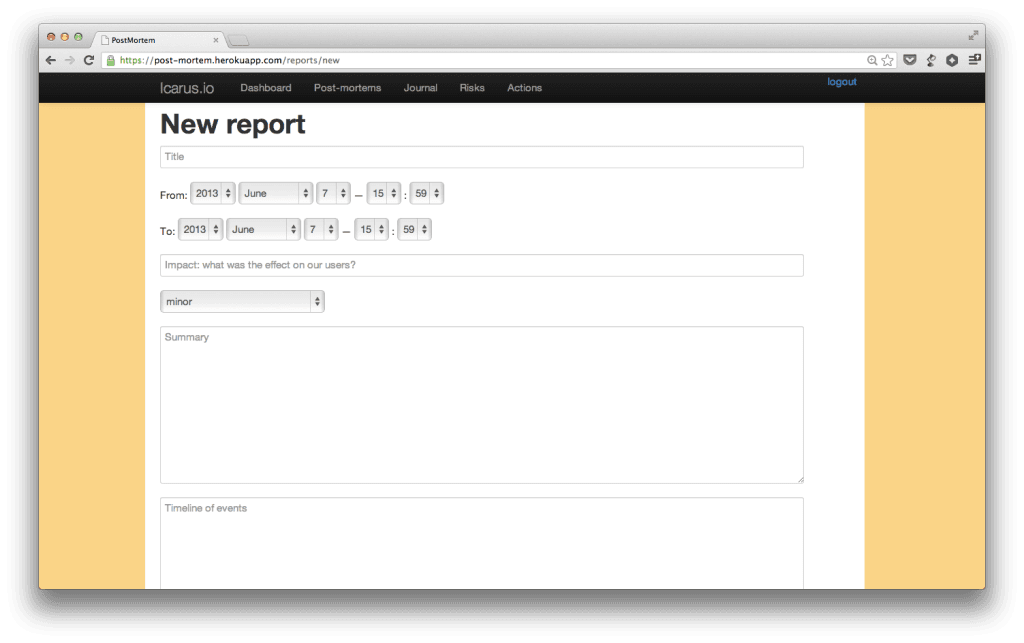
As I mentioned in another article, we see process as a necessary evil that lets us focus the majority of our time on important things. Part of this involves making computers do as much of our work as possible. Any app that can make a process more consistent and bearable is a great asset.
What makes a good post-mortem
While we’re still perfecting our technique for post-mortems, we bear the following goals in mind:
- Educate other technical team members as to why an incident occurred
- Highlight the impact (if any) to our customers (for stakeholders and support)
- Commit to some changes that will reduce the likelihood of the same thing happening again
After an incident, the primary person who dealt with it (usually the person who was on call) writes up the post-mortem. At the next weekly meeting, we go through recent post-mortems as a team and create actions for them. We go through this if the incident is large (involved an outage) or small (could have become dangerous).
Our post-mortems require the following:
- Time frame it occurred in
- Impact to our users
- Timeline of events
- Conclusions
- Actions
The importance of a timeline
It’s generally not good enough just to say that a process died, or that a particular user was acting in an unpredictable way. We need to show what broke, in what order and how we reacted.
Doing this teaches people about symptoms to look for in future incidents, and where to look for them. It also allows us to have a well-informed discussion about how effective our response was.
Timelines are a fundamental part of our reports. Piecing together notes from the event afterwards is a big pain however, and leads to process friction (people not wanting to do it).
We reduce this friction by including logs from our chatroom in the report. This shows how people reacted, what they were thinking, and how long things took. When there are consequences we can see the fallout from them. Aware that logs will be recorded, we even make suggestions for things we’d like to change in IRC while we’re working, acting as a real-time stream of consciousness that captures our impressions while they’re still fresh.
Having monitoring systems report into the incident channel on IRC is also a great help here. It anchors the stream of consciousness to definite measurable changes in the system status, further reducing the friction in creating an accurate timeline later – we get a solid base just by curating the chat logs.
Anything we can add to a report to show how the events unfolded is very useful for later discussion. We attach graphs from munin, or our other internals tools where it helps.
Committing to and recording actions
Committing to actions that might prevent similar incidents is a key part of our post-mortems. It’s not good enough to say in passing “oh it would be good if we had a nagios alert on X”, because it’ll rarely get prioritised. We also want to see trends like open actions that could could have prevented an incident.
We discuss actions as a group and attach them to the report. These are stored in the post-mortem system, but also create Github issues. The created issues are labelled as ‘post-mortem’ and include a link to the report to help with our normal backlog prioritisation.
We’ve found that methodically recording incidents we encounter allows us to deal with issues systematically, and ensures we learn from our mistakes.






© 2026 Pusher Ltd. All rights reserved.
Pusher Limited is a company registered in England and Wales (No. 07489873) whose registered office is at MessageBird UK Limited, 3 More London Riverside, 4th Floor, London, United Kingdom, SE1 2AQ.