- Products

- Developers
- User stories
- Blog
- Pricing

Counting connections at scale
Building connection counting in a scaleable way is tricky. Find out how we fixed a meandering solution by leveraging our HTTP API processes.
Introduction
We recently shipped a new experimental feature: Pusher Channels can now respond with the number of connections that are subscribed to a channel at the time of publish. It can also return the number of users in a presence channel at the time of publish.
You can read more about how to use it in our docs.
This feature leverages the connection counting functionality that we already expose through our HTTP API via the [GET /channels](https://pusher.com/docs/channels/library%5Fauth%5Freference/rest-api#get-channels-fetch-info-for-multiple-channels-) and [GET /channel/<channel_name>](https://pusher.com/docs/channels/library%5Fauth%5Freference/rest-api#get-channel-fetch-info-for-one-channel-) endpoints.
Building connection counting in a scaleable way is tricky, so in this post we’ll give you the details of how we solved this!
A flawed solution
At a high level, the part of our system that handles WebSocket connections looks like this:
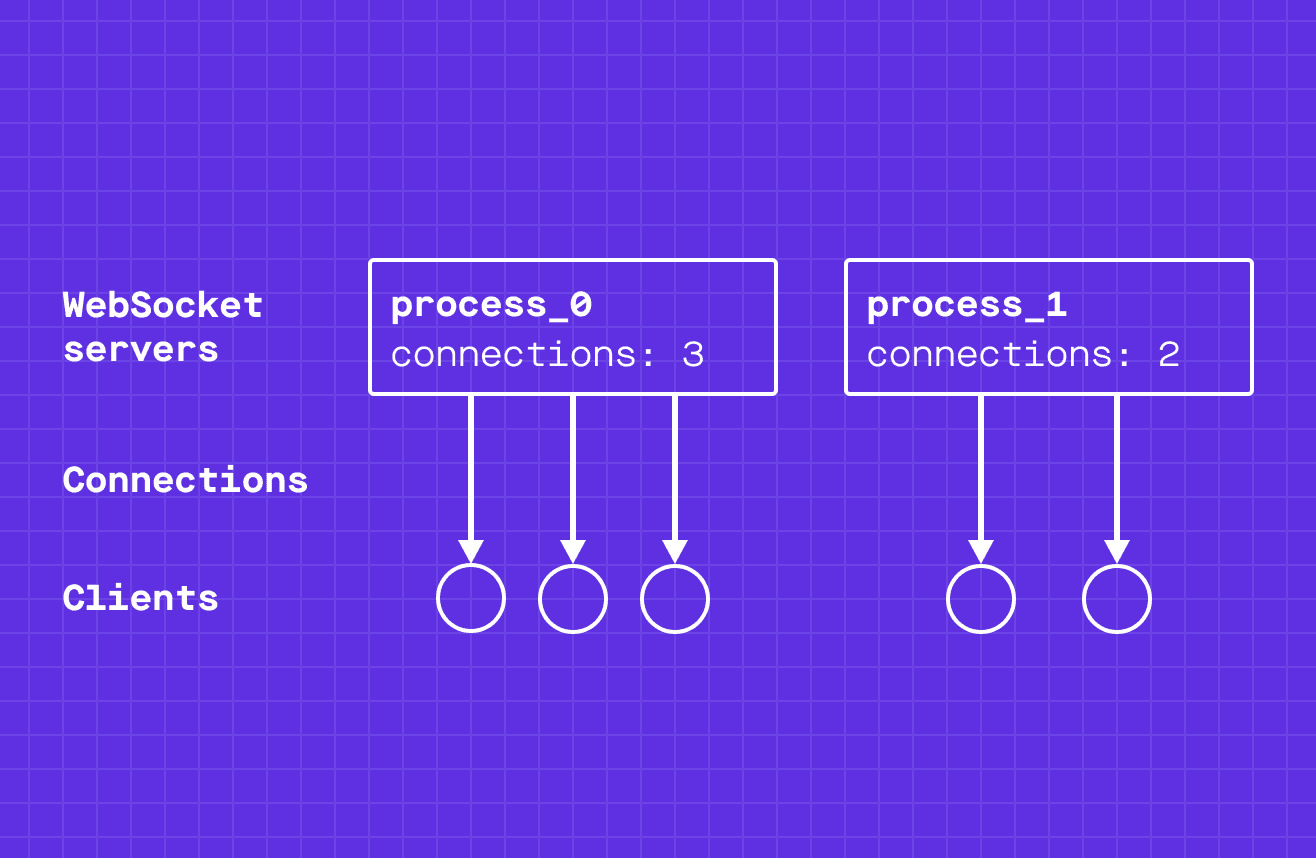
For simplicity let’s assume that all connections are to a single channel of a Channels app for now.
Having multiple WebSocket servers provides us with horizontal scalability and fault tolerance. If you are interested in learning more about how we scale our system, you should read our post on how Channels has delivered 10,000,000,000,000 messages (as of February 2021 this number has reached over 26 trillion).
But having multiple servers introduces a problem: no individual server will be able to tell us the total message count for a channel.
To solve this, we made each server process update a global counter whenever subscriptions are added or removed from a channel. We use redis to store these counters. To horizontally scale the redis process, we shard across multiple redis processes by the app ID.
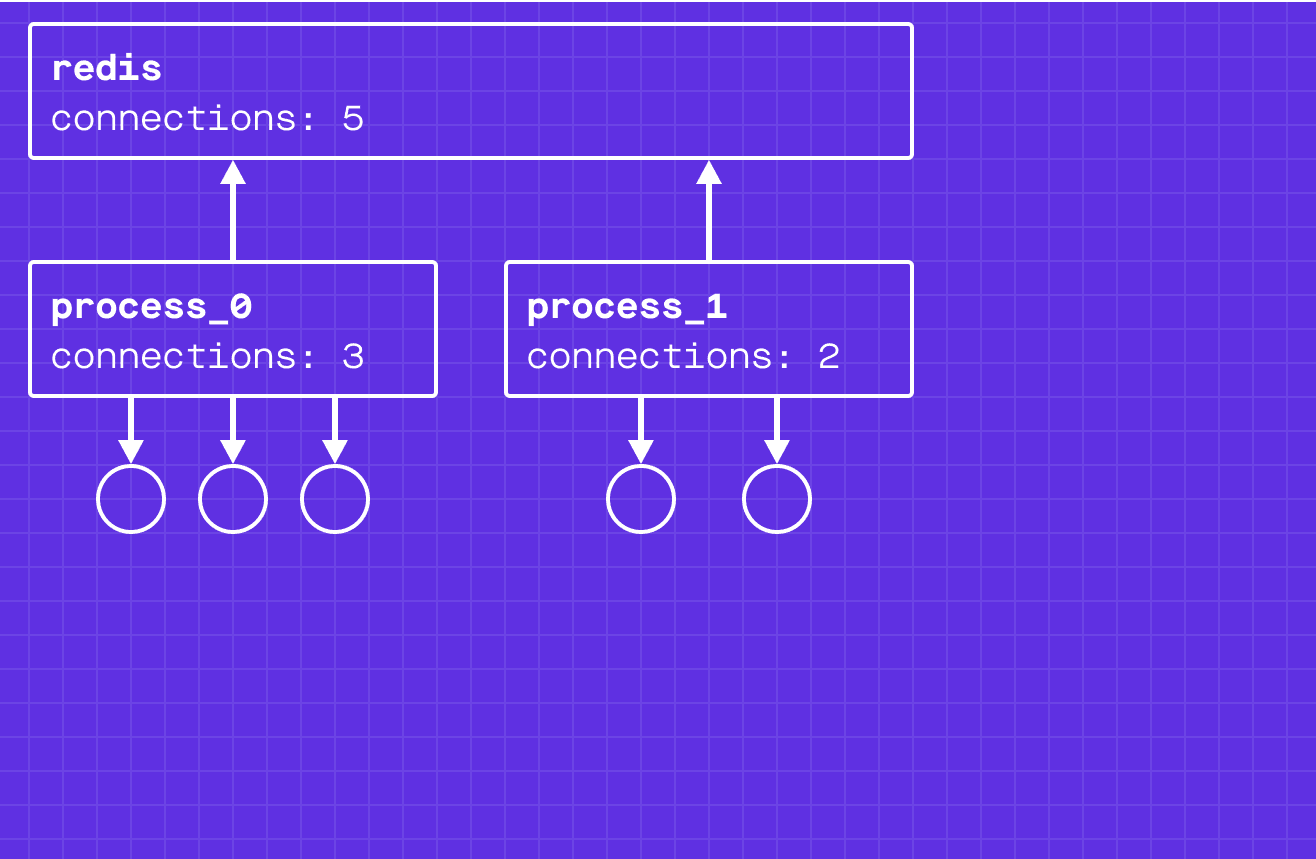
There was a problem with this approach. What if a server process crashed? In this case the connections would break, but the process would not decrement the counter in redis. The fundamental problem is that the connection/disconnection events on the server and updating redis are not atomic. This can cause inconsistencies between the counts on the servers and counts in redis, which will never resolve.
Rather than prevent these inconsistencies from happening in the first place, we created a process that fixed them when they occurred. This means connection counts could occasionally be inconsistent for short periods of time, and is one of the reasons these connection counts were “best effort”.
*Note that these counts are not what we use for billing or limiting — those counts are aggregated in a separate system that is fully optimised for reliability, so your billing counts are always correct.
Fixing the inconsistencies
In addition to updating the global count, the WebSocket server process also updates a connection count just for its process (connections_process_<pid>). To ensure these two writes are atomic, we use redis transactions.
Each WebSocket server process periodically writes its process id and the current timestamp to redis. The state now looks like:
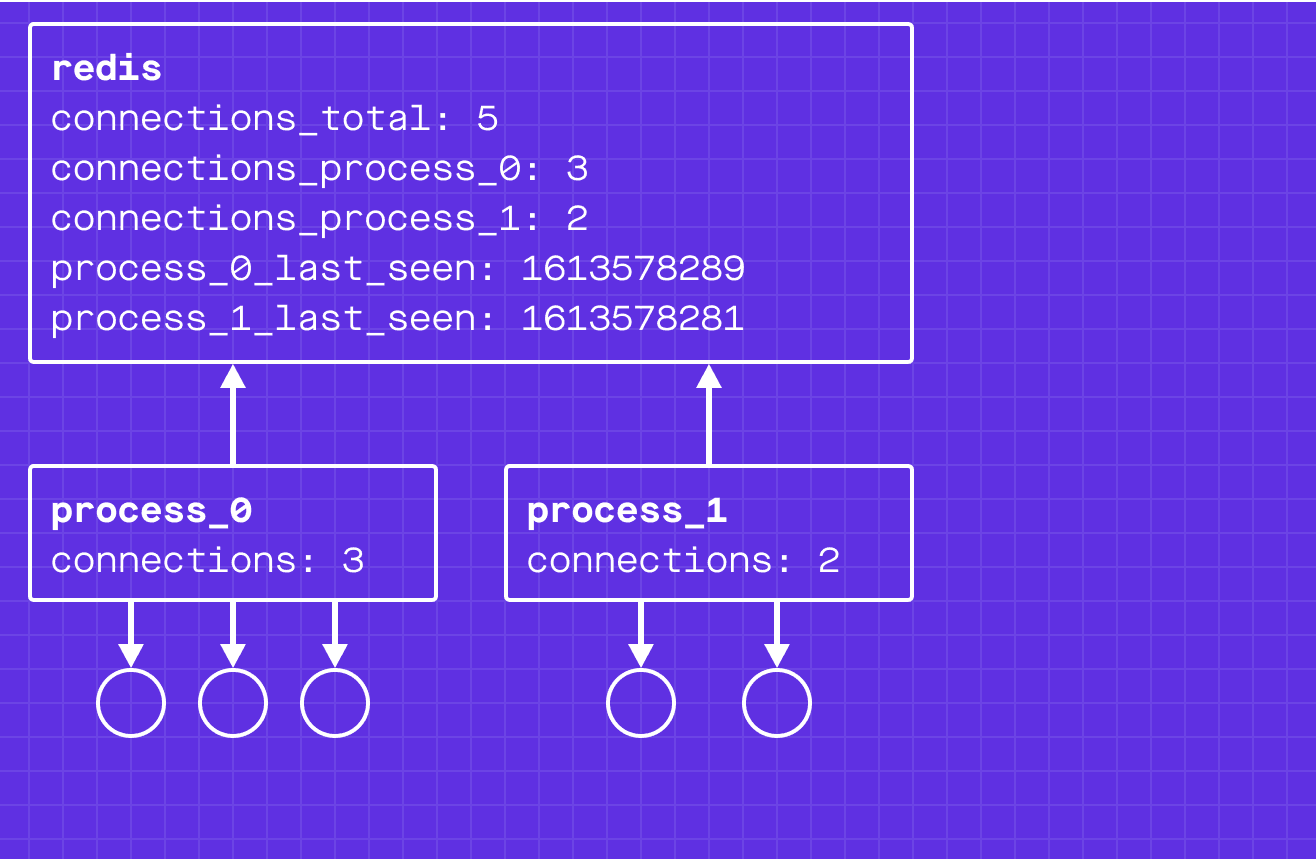
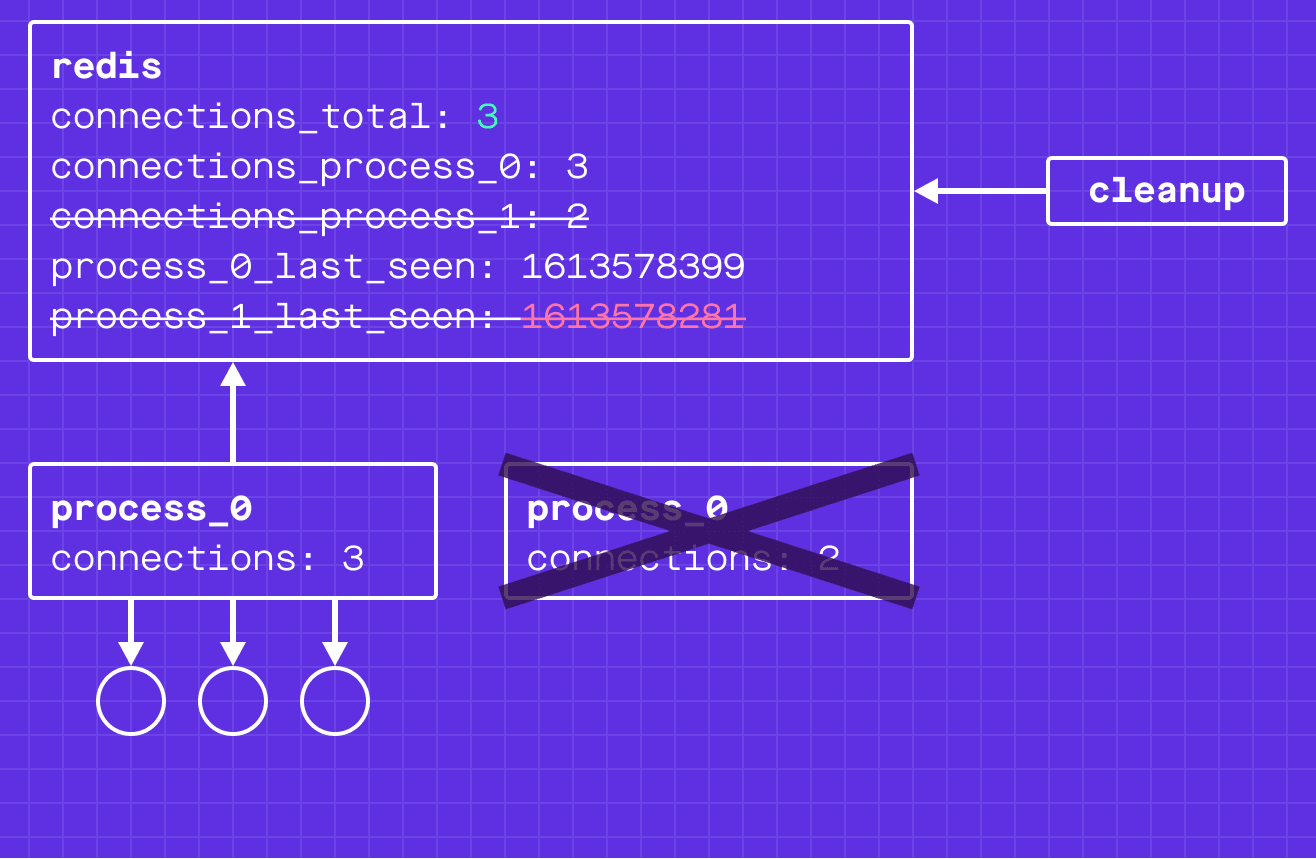
Oh no! process_1 has died and is not updating the process_1_last_seen timestamp. Our global connection count is inconsistent with reality!
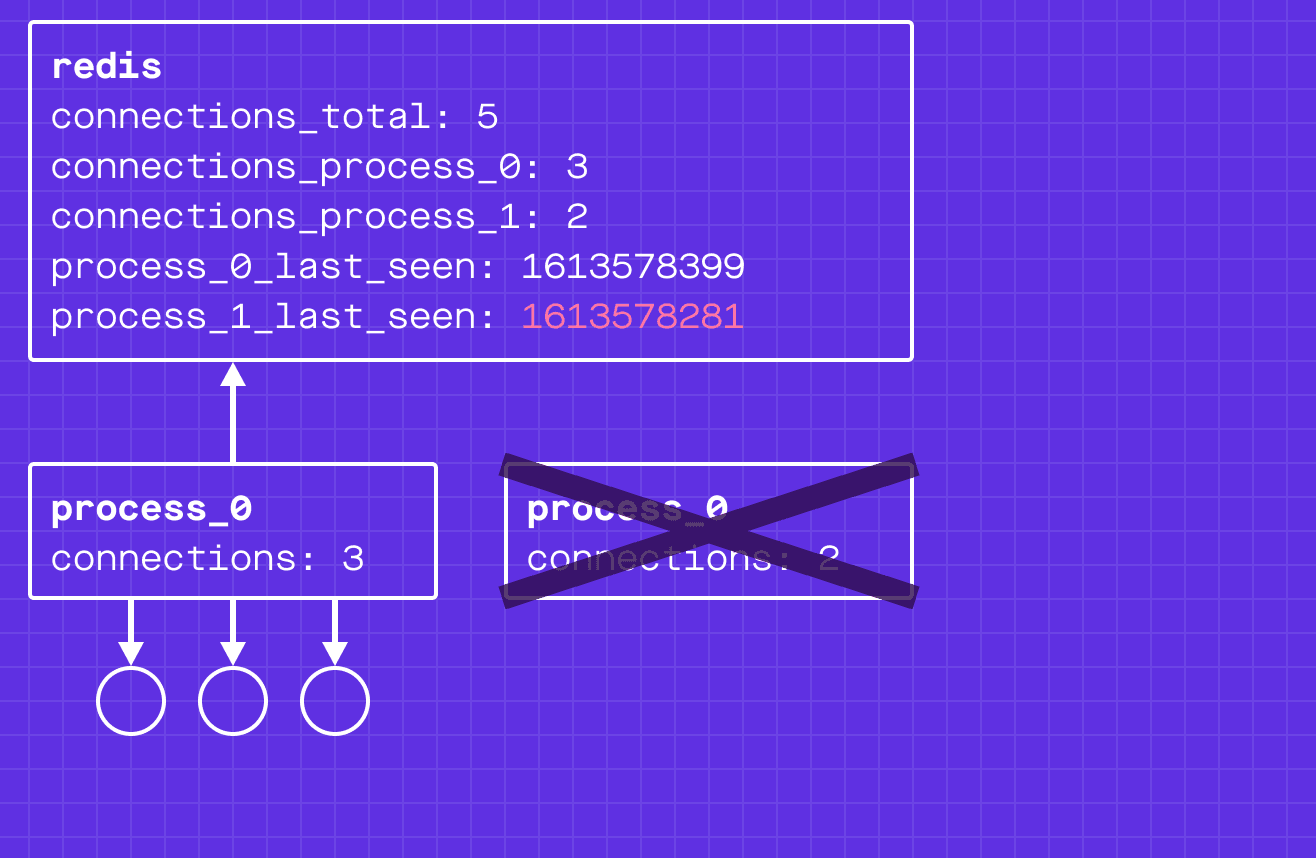
This is where a cleanup process comes in: it periodically scans the timestamps, and if one is too old, it assumes the process is dead.
For a dead WebSocket server process, the cleanup process will decrement the connections_process_<pid> from the connections_global and remove the connections_process_<pid> key. Again, this is made atomic through redis transactions.
To make this process fault tolerant, cleanup process runs as an active/passive pair. The active process refreshes a lease in redis; if the active process crashes, the passive process will acquire the lease and take up the workload.
Now that we have the counts in redis, we are ready to serve them to our users through our HTTP API processes!
For the same content in video/presentation format, you should check out James Fisher’s talk from Redis Day London.
This feature is currently available in our Experimental program, so we’d love to hear your feedback! To see how to use it read more in our docs.






© 2026 Pusher Ltd. All rights reserved.
Pusher Limited is a company registered in England and Wales (No. 07489873) whose registered office is at MessageBird UK Limited, 3 More London Riverside, 4th Floor, London, United Kingdom, SE1 2AQ.